
type
status
date
slug
summary
tags
category
icon
password
书籍
011-Organizations-VPCの共有-RAM
理論
AWS(Amazon Web Services)は、企業や組織が複数のAWSアカウントを使用してインフラを管理できるようにするための機能を提供しています。これに関連する重要なコンセプトを理解することは、質問に対する最適な解答を導くための鍵となります。以下に、関連する前提知識を整理します。
1. AWS Organizationsとは
AWS Organizationsは、複数のAWSアカウントを一元的に管理するためのサービスです。このサービスにより、組織内で複数のアカウントを作成・管理し、アカウント間でのリソースやポリシーの一貫した適用が可能となります。
- マスターアカウント:AWS Organizationsを管理するための最上位アカウントで、組織全体に対する設定や管理を行います。
- メンバーアカウント:AWS Organizations内で管理されるアカウントで、組織の方針に基づいてリソースを利用します。
2. VPC(Virtual Private Cloud)とは
VPCは、AWSの仮想ネットワークで、AWSリソース(EC2インスタンス、RDSインスタンスなど)を配置するための基盤となります。VPCは、インターネットに接続するためのインターフェースを提供するほか、サブネット(ネットワーク分割)やルートテーブル、セキュリティグループ、ネットワークACLなど、ネットワーク設定の管理が可能です。
- サブネット:VPC内のIPアドレス範囲を分けたネットワークの単位。サブネットはVPCの中で異なるアベイラビリティゾーンに配置できます。
- インターネットゲートウェイ:VPCとインターネットとの接続を提供します。
3. VPCの共有とリソース管理
複数のアカウントで同一のVPCを利用したい場合、通常はVPCピアリングを使用しますが、管理者がVPCを他のアカウントで利用可能にする方法として「リソースの共有」を行うことができます。
- リソースアクセスマネージャー(RAM):AWS Resource Access Manager(RAM)は、AWSアカウント間でリソース(VPCサブネット、セキュリティグループ、Route 53ホストゾーンなど)を共有するためのサービスです。
- リソース共有:特定のリソース(例えば、VPC内のサブネット)を共有することができ、共有されたリソースは、他のAWSアカウントでも利用可能になります。共有者は、リソースの管理者の役割を担うが、リソースを利用する者(個別アカウント)は管理権限を持たず、利用のみが可能です。
4. AWS IAM(Identity and Access Management)
IAMは、AWSリソースへのアクセス制御を行うためのサービスです。個別アカウントに対して、リソースの作成や操作に関する権限を付与することができます。
- ポリシー:IAMユーザーやグループに適用するアクセス権限を定義します。例えば、EC2インスタンスを起動する権限やVPCのサブネットにリソースを作成する権限を個別に設定することができます。
- ロール:AWSリソースに対するアクセス権限を付与するためのIAMロールを作成し、必要に応じて他のAWSアカウントやサービスに割り当てることができます。
5. VPCの管理とアクセス権限の設計
管理カウントがVPCを管理し、個別アカウントに対してそのVPC内のサブネットでリソースを作成する権限を与える必要があります。具体的には、個別アカウントがサブネットを作成したり管理したりする権限を持たない一方で、そのサブネット内でリソース(EC2インスタンスなど)を作成する権限を付与します。
- 管理者の権限とユーザーの権限の分離:管理カウントがネットワーク全体を管理し、個別アカウントがVPC内のサブネットを利用してリソースを作成できるようにするため、IAMポリシーやリソースアクセスマネージャー(RAM)の設定を行います。
6. AWS Organizations内でのリソース管理
AWS Organizationsを活用して、個別アカウントに特定のリソース(VPCやサブネット)を共有し、それに対して必要な権限のみを付与する形でアクセスを制御します。
- リソースの共有設定:管理カウントで作成したVPCサブネットなどのリソースを、AWS Resource Access Managerを利用して他の個別アカウントと共有し、共有されたアカウントがそのリソースを使用できるように設定します。
まとめ
AWS Organizations、VPC、IAM、Resource Access Managerなどを活用することで、個別アカウントにネットワークの管理権限を与えずに、VPC内のサブネットにリソースを作成する権限を提供することができます。この仕組みを活用することで、インフラアカウントはネットワーク全体を一元管理しつつ、各個別アカウントがリソースを作成する権限を持つことができます。
一問道場
背景:
- 会社は複数のAWSアカウントを使っています。AWS Organizationsを使ってこれらのアカウントを管理しています。
- インフラチームには、専用のアカウント(インフラアカウント)があり、このアカウントにはVPC(仮想プライベートクラウド)があります。このVPCを使って、全アカウントで共通のネットワークを管理します。
- 他の個別アカウント(ユーザーアカウント)にはネットワークを管理する権限は与えませんが、インフラアカウントが管理しているVPC内のサブネットにリソースを作成することはできます。
要件:
- 個別アカウントは自分のVPCネットワークを管理できないが、インフラアカウントで管理されている共通ネットワークを利用してリソースを作成することができるようにする。
- インフラアカウントのVPCを他のアカウントに共有する方法を考えてください。
質問:
この要件を満たすために必要な手順はどれか、最も適切なものを2つ選んでください。
選択肢:
- A インフラアカウントにトランジットゲートウェイを作成する。
- B AWS Organizationsの管理アカウントでリソース共有を有効にする。
- C 各アカウントにVPCを作成し、インフラアカウントのVPCと同じCIDR範囲を設定し、ピアリング接続を行う。
- D インフラアカウントでAWS Resource Access Managerを使い、特定のAWS OrganizationsのOU(組織単位)にネットワークを共有し、サブネットを関連付ける。
- E インフラアカウントでAWS Resource Access Managerを使い、特定のAWS OrganizationsのOUにネットワークを共有し、プレフィックスリストを関連付ける。
解説:
- A: トランジットゲートウェイは複数のVPCを接続するためのサービスです。異なるアカウントのVPCを接続するのに有効ですが、単純にサブネットを共有するだけではなく、VPC接続を管理する手順が必要です。
- D: AWS Resource Access Manager(RAM)を使うことで、インフラアカウント内のサブネットやネットワーク資源を、他のアカウントで使用できるように共有することができます。これにより、個別アカウントがサブネット内にリソースを作成できるようになります。
このように、選択肢を整理することで、問題の要件がより明確になります。また、解決策の内容も簡潔に説明しました。
012-PrivateLinkを使用したプライベート接続の構築
理論

1. AWS PrivateLink
AWS PrivateLinkは、AWSサービスまたはサードパーティのアプリケーションに対してインターネットを経由せず、安全にプライベートネットワーク経由で接続するためのサービスです。
- インターフェイスVPCエンドポイント: 特定のAWSサービスやエンドポイントサービス(サードパーティのアプリケーションなど)に接続するために使用される。
- 主な特徴:
- インターネットを経由せず、AWSネットワーク内で通信。
- エンドポイントにセキュリティグループを適用可能で、アクセス制御が柔軟。
- サービス提供者と消費者が別々のVPCに存在する場合でも利用可能。
AWS PrivateLinkの通信特性
- 単方向通信:
- AWS PrivateLinkでは、インターフェイスVPCエンドポイントを通じて、サービスの消費者(Client側)がサービスプロバイダー(Provider側)にアクセスする仕組みです。
- 消費者側(エンドポイントが存在するVPC)からプロバイダー側(サービスが提供されるVPC)へのリクエストは可能ですが、その逆方向の通信はサポートされていません。
- 消費者とプロバイダーの分離:
- 消費者側はプロバイダーのVPCに関する情報(例: IPアドレス範囲やVPC ID)を知る必要がありません。
- プロバイダーも消費者のVPCに直接アクセスすることはできず、完全に分離されています。
- 双方向の通信が必要な場合の代替案:
- AWS PrivateLinkではデータやリクエストを送信する方向が限定されるため、双方向通信が必要な場合には別の方法を検討する必要があります。例:
- VPCピアリング: 双方向の通信が可能。
- AWS Transit Gateway: より複雑な接続環境を管理可能。
単方向通信のメリット
- セキュリティの向上:
- 通信の方向を明確に制限することで、不要なアクセスや潜在的な脅威を防ぐ。
- ネットワーク分離:
- サービス提供者と消費者が分離されているため、接続先の詳細情報を隠すことが可能。
まとめ
AWS PrivateLinkは「クライアント(消費者)がサーバー(プロバイダー)にリクエストを送る」という単方向通信が基本です。双方向通信が必要な場合は、VPCピアリングや別のサービスを利用する方が適しています。
2. AWS Site-to-Site VPN
AWS Site-to-Site VPNは、オンプレミス環境や他のAWS環境との間で安全なVPN接続を確立するサービスです。
- 主な特徴:
- 暗号化されたトンネルで通信。
- インターネットを経由するため、完全なプライベート接続ではない。
- ネットワークACLやセキュリティグループでアクセスを制御可能。
3. VPCピアリング
VPCピアリングは、異なるAWSアカウントまたは同一アカウント内の2つのVPC間で安全なネットワーク接続を確立する方法です。
- 主な特徴:
- 双方向でアクセス可能な接続を構築。
- プライベートIPアドレスを使用して通信。
- ルートテーブルの設定が必要で、アクセス範囲の制御が難しい場合もある。
4. アクセス制御と最小権限の原則
- セキュリティグループ: 特定のVPCリソースに対するアクセスを許可または拒否するルールを設定。細かい制御が可能。
- ネットワークACL: サブネットレベルでのアクセス制御。セキュリティグループより粗い制御。
- 最小権限の原則: 必要最低限の権限のみを付与し、不要なアクセスを防ぐ。
関連するAWSサービスのユースケース比較
サービス | 特徴 | 使用例 |
AWS PrivateLink | 完全にプライベートな接続を提供。インターネットを経由せず、セキュリティが高い。 | サードパーティのSaaSアプリケーションやAWSサービスへのアクセス。 |
Site-to-Site VPN | 暗号化された接続だが、インターネットを経由するため完全なプライベート通信ではない。 | オンプレミス環境とAWS間の接続。 |
VPCピアリング | 双方向のプライベート接続。設定が簡単だが、大規模な接続管理には向かない。 | 同じAWSアカウントまたは異なるアカウントのVPC間通信。 |
実践
Privatelinkとは、
「VPC間のPrivate通信を許可する設定および構成」を指しています。VPC Peeringとの違いは、「特定の通信のみを許可できる」点です。それでは、構築を進めましょう。
構成図

ステップ 1:VPC構築
下記のVPCを構築します。
リソース・サービス | 設定・要点 |
VPC(privatelink-A-vpc) | サービス利用側のVPC |
ㅤ | - Availability Zone-A/C に Public/Private サブネットを作成 |
ㅤ | - NATゲートウェイを1つ作成 |
VPC(privatelink-B-vpc) | サービス提供側のVPC |
ㅤ | - Availability Zone-A/C に Public/Private サブネットを作成 |
ㅤ | - NATゲートウェイを1つ作成 |
この表を参考に構築を進めてください。


ステップ 2:EC2構築
下記のEC2を構築します。
リソース・サービス | 設定・要点 |
Security Group (EC2-A-sg) | サービス利用側EC2(EC2-A)のSG。インバウンドルールは後ほど設定します。 |
Security Group (EC2-B-sg) | サービス提供側EC2(EC2-B)のSG。インバウンドルールは後ほど設定します。 |
IAMロール (SSM-role) | EC2にSSM接続をするためのIAMロール。AmazonSSMManagedInstanceCoreポリシーをアタッチします。 |
EC2 (EC2-A) | サービス利用側のEC2。- 作成したSGとIAM Roleをアタッチ。- VPC-A AZ-aのPrivate Subnetに配置します。 |
EC2 (EC2-B) | サービス提供側のEC2。- 作成したSGとIAM Roleをアタッチ。- VPC-B AZ-cのPrivate Subnetに配置します。 |
EC2-B ユーザーデータ | #!/bin/bash
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
touch /var/www/html/index.html
echo "Hello AWS!" | tee -a /var/www/html/index.html |


ステップ 3:NLB構築
下記のEC2を構築します。
リソース・サービス | 設定・要点 |
Security Group (NLB-B-sg) | NLB(NLB-B)のSG。インバウンドルールは後ほど設定します。 |
Target Group (NLB-B-tg) | NLBからEC2に接続するためのTG。
- プロトコル: TCP:80
- ヘルスチェックパス: /index.html
- ターゲット: EC2(EC2-B) |
Network Load Balancer (NLB-B) | PrivateLinkとしてサービスを提供するためのNLB。
- 内部向けNLBとして構築。
- privatelink-B-vpc のAvailability Zone-A/Cにマッピング。
- 上記のSGをアタッチ。
- TCP:80番のリスナーに上記TGをアタッチ。 |
この表を参考に構築を進めてください。

ステップ 4:NLBからEC2への接続許可
リソース・サービス | 設定・要点 |
Security Group(EC2-B-sg) | HTTP(TCP: 80)に対し、
NLBのSG(NLB-B-sg)の通信を許可します。 |

エンドポイントとエンドポイントサービスの違い
- エンドポイント: インターネットを経由せず、VPCからS3などにアクセスするための接続口。
- エンドポイントサービス: 自分のVPCで構築したNLB(ネットワークロードバランサー)を使って、他のVPCから自分のサービスに接続できるようにする機能。
まとめ
- エンドポイントはAWSのサービスに接続するための入口。接続したい側、消費者が構築
- エンドポイントサービスは、他のVPCに自分のサービスを提供するための仕組みです。提供者が構築
ステップ 5:提供者側の設定
下記のエンドポイントサービスを作成します。
リソース・サービス | 設定・要点 |
VPC Endpoint Service(privatelink-B-vpces) | Privatelinkを構成するサービスです。
サービス提供側VPCに構築したNLB(NLB-B)をアタッチします。
サポートされいているIPアドレスタイプにはIPv4を設定します。 |
ステップ 6:利用者側の設定
下記のエンドポイントを作成します。
リソース・サービス | 設定・要点 |
Security Group(privatelink-A-vpce-sg) | VPC EndpointのSGです。
HTTP(TCP: 80)に対し、EC2のSG(EC2-A-sg)の通信を許可します。 |
VPC Endpoint(privatelink-A-vpce) | Privatelinkの入り口となるサービスです。
サービス利用VPCに構築されたEC2と同一のサブネットに配置します。
・ タイプ:NLB と GWLB を使用するエンドポイントサービスサービス名には控えておいたサービス名を入力し、サービスの検証を押下します。
・サブネット:ap-northeast-1aのPrivateSubnetのIDを選択します。
・セキュリティグループ:privatelink-A-vpce-sg |
ステップ 7:提供者側の承諾
リソース・サービス | 設定・要点 |
VPC Endpoint Service(privatelink-B-vpces) | エンドポイント接続タブにて作成したエンドポイントがPending acceptanceとなっているので、アクション → エンドポイント接続リクエストの承諾を選択します。 |
ステップ 8:ネットワーク到達性の確認
VPC Reachability Analyzer を利用してネットワークの到達性を確認します。以下の手順で進めてください。
- VPC Reachability Analyzerの起動
AWSマネジメントコンソールの検索バーから「VPC Reachability Analyzer」を検索してアクセス。
- 料金注意
実行1回につき 0.10USD が請求されます。検証のため2回失敗を試みる場合、料金が気になる方は実施前に内容を確認してください。
- 設定手順
- 「パスの作成」を選択。
- 分析対象の送信元・送信先を設定し、分析を実行。
- 分析結果
- 到達性を確認可能。
- Elastic Network Interface(ENI) や Security Group(SG) の通過状況が詳細に表示され、トラブルシューティングに役立ちます。
- 期待結果
- 実際の結果
- 原因の確認
リソース・サービス | 設定・要点 |
パスの作成と分析(EC2A-B) | 到達性の設定をします。
・ 送信元タイプ:instances
・送信元:EC2-A (id)
・送信先タイプ:instances
・送信先:EC2-B (id)プロトコル:TCP |
EC2間接続の確認結果
EC2-AとEC2-B間で接続が可能になるはずが
「到達不可能」 と表示されました。
詳細を確認すると、次のエラーが発生:
「セキュリティグループの ingress ルールが適用されていない」など

VPC Reachability Analyzerを参照しながら、SGを修正していきます

NLBPrivateLinkの通信セキュリティの解除
デフォルトの設定では、NLBに設定されているSGがPrivateLinkの通信に適用されます。 PrivateLinkの通信セキュリティはエンドポイントのSGで制御しているため、この関連付けを解除します。
リソース・サービス | 設定・要点 |
NLB(NLB-B) | セキュリティタブより編集ボタンを押下します。PrivateLink トラフィックにインバウンドルールを適用する のチェックを外します。 |
(再度)ネットワーク到達性を確認する
設定が完了したので、再度、到達性の検証をします。 2回目以降は通信先を設定する必要は無く、先ほど作成したパス(EC2A-B)を選択し、
パスの分析ボタン → 確認ボタンを押下します。しかし、またもや「到達不可能」と出てしまいました!
詳細を見てみると、
ロードバランサー loadbalancer/net/NLB-B/xxx のリスナーは、いずれも適用されません。というエラーの様です。 その原因は、クロスゾーン負荷分散を有効化する
この接続が失敗した理由は、EC2-A/Bがそれぞれ別のAZに配置されていたためです。 デフォルトの設定では同一のAZ内で通信を行うため、AZ間で通信できるようにするためには、 NLBの設定から「クロスゾーン負荷分散」機能を有効化する必要があります。

NLBがAZをまたいだルーティングを可能にするために、クロスゾーン負荷分散の設定を行います。
リソース・サービス | 設定・要点 |
NLB(NLB-B) | NLBを選択し アクション → ロードバランサーの属性を編集を選択します。ロードバランサーのターゲット選択ポリシー項目でクロスゾーン負荷分散を有効にするを選択します。 |
設定編集画面より、NLB以降でAZ間に通信ができるイメージ画像に変わります。
(再々度)ネットワーク到達性を確認する
今度こそ、設定不足が無いかチェックしながら、再々確認します。
「到達可能」となりました!

実際に接続してみる
サービス利用側EC2(EC2-A)からサービス提供EC2(EC2-B)のWebページが閲覧できることを確認します。
EC2-Aのアクセス先は、作成したエンドポイントとなるので、アクセス先DNS名を取得します。
リソース・サービス | 設定・要点 |
VPC Endpoint(privatelink-A-vpce) | 消費者側のエンドポイントのDNS名を取得します。 詳細タブより、DNS名を控えておきます。合わせて、サブネットタブより、IPv4アドレスを控えておきます。 |
EC2-AにSSMでログインし、以下のコマンドを用いてWebページへアクセスします。

最後に
今回のHTTP:80を使用したWebサーバの設定は、独自のサービスやプロトコルに置き換えることで、AWSネットワーク間で安全な通信を実現できます。また、VPC Reachability Analyzerを活用すれば、インスタンス以外も送信元/先に設定可能で、送信ヘッダーの制御を含め柔軟なテストケースを作成できます。

一問道場
質問 #12
ある企業がサードパーティのソフトウェア・アズ・ア・サービス(SaaS)アプリケーションを利用したいと考えています。このSaaSアプリケーションは、いくつかのAPI呼び出しを通じて利用され、AWS上のVPC内で動作しています。企業は、自社のVPC内からこのSaaSアプリケーションを利用します。
要件
- インターネットを経由しないプライベート接続を使用すること。
- 企業VPC内のリソースが外部からアクセスされないこと。
- すべてのアクセス許可は最小権限の原則に従うこと。
選択肢
A.
- AWS PrivateLinkインターフェイスVPCエンドポイントを作成する。
- このエンドポイントをサードパーティのSaaSアプリケーションが提供するエンドポイントサービスに接続する。
- セキュリティグループを作成してエンドポイントへのアクセスを制限し、このセキュリティグループをエンドポイントに関連付ける。
B.
- サードパーティのSaaSアプリケーションと企業のVPCの間にAWS Site-to-Site VPN接続を作成する。
- ネットワークACLを設定してVPNトンネル間のアクセスを制限する。
C.
- サードパーティのSaaSアプリケーションと企業のVPCの間にVPCピアリング接続を作成する。
- ルートテーブルを更新して、ピアリング接続に必要なルートを追加する。
D.
- AWS PrivateLinkエンドポイントサービスを作成する。
- サードパーティのSaaSプロバイダーに、このエンドポイントサービス用のインターフェイスVPCエンドポイントを作成するよう依頼する。
- このエンドポイントサービスへのアクセス許可を特定のサードパーティSaaSプロバイダーのアカウントに付与する。
どのソリューションがこの要件を満たすでしょうか?
解説
問題の要件
- プライベート接続の利用: インターネットを経由しない通信が必要。
- 企業VPC外からのアクセス禁止: サードパーティのSaaSアプリケーションへの通信のみを許可。
- 最小権限の原則: 必要最低限のアクセス許可を設定すること。
各選択肢の評価
選択肢 A: AWS PrivateLink を使用
AWS PrivateLinkインターフェイスVPCエンドポイントを作成し、サードパーティSaaSアプリケーションのエンドポイントサービスに接続する。セキュリティグループを作成し、アクセスを制限する。
- 要件適合性:
- プライベート接続: AWS PrivateLinkはAWSネットワークを利用するため、インターネットを経由しない。
- 企業VPC外からのアクセス禁止: 接続はエンドポイント経由で行われ、企業VPC外からの直接アクセスは不可能。
- 最小権限: セキュリティグループを使用してアクセスを限定できる。
- 評価: 要件をすべて満たしており、最適な解決策。
✅ 適切
選択肢 B: AWS Site-to-Site VPN
サードパーティのSaaSアプリケーションと企業VPC間でSite-to-Site VPN接続を作成し、ネットワークACLでアクセスを制限する。
- 要件適合性:
- プライベート接続: VPNはインターネットを経由するため、完全なプライベート接続にはならない。
- 企業VPC外からのアクセス禁止: VPN接続自体が双方向通信を可能にするため、外部リソースが企業VPCにアクセスできる可能性がある。
- 最小権限: ネットワークACLで制限可能だが、完全に分離された構成ではない。
- 評価: インターネット非経由の要件を満たさず不適切。
❌ 不適切
選択肢 C: VPC Peering
サードパーティのSaaSアプリケーションと企業VPCの間にVPCピアリング接続を作成し、ルートテーブルを更新する。
- 要件適合性:
- プライベート接続: VPC PeeringはAWSネットワーク内で通信するため、インターネットを経由しない。
- 企業VPC外からのアクセス禁止: VPC Peeringは双方向通信が可能であるため、サードパーティが企業VPCにアクセスできてしまう。
- 最小権限: 双方向通信のため、不要なアクセスリスクが増加。
- 評価: 双方向通信が可能であるため要件に適合しない。
❌ 不適切
選択肢 D: 消費者がエンドポイントサービスを作成
- 要件適合性:
- プライベート接続: AWS PrivateLinkはプライベート接続を提供。
- 企業VPC外からのアクセス禁止: エンドポイントサービスは企業側で提供されるため、構成が要件と逆になる。
- 最小権限: 消費者側がサービスを提供する形になるため、管理負担が増加。
企業側でAWS PrivateLinkエンドポイントサービスを作成し、サードパーティにエンドポイントを設定させる。
- 評価: 構成が要件に沿っておらず不適切。
❌ 不適切
結論
最適な解決策は 選択肢 A: AWS PrivateLink を使用することです。このソリューションは以下の理由で要件を満たします。
- インターネットを経由せず、AWSのプライベートネットワーク内で通信する。
- エンドポイントを介した接続のみを許可し、企業VPC外からのアクセスを遮断。
- セキュリティグループを活用して最小権限を適用可能。
答え: A
013-AWS Systems Manager
理論
サーバーのパッチ管理に関する前提知識
1. パッチ管理の重要性
- 目的: ソフトウェアやOSの脆弱性を修正し、システムのセキュリティと安定性を確保する。
- 利点:
- セキュリティ向上: 攻撃を未然に防ぐ。
- 運用の安定化: バグの修正でシステム障害を回避。
- 規制対応: コンプライアンス要件の達成。
2. パッチ管理プロセスの要素
- 検出: 適用が必要なパッチを特定する。
- 適用: 適切な方法でパッチを配布・インストールする。
- 確認: 適用後に正常動作を確認し、コンプライアンスを記録する。
- レポート: 適用状況を経営層や監査用に報告する。
3. AWSでのパッチ管理ツール
AWS Systems Manager (SSM)
- 主な機能:
- Patch Manager: サーバーやインスタンスにパッチを適用。
- Automation: スクリプトを自動化して管理作業を効率化。
- Compliance Reporting: パッチ適用状況をレポート化。
- 適用環境:
- オンプレミスサーバー
- Amazon EC2インスタンス

AWS Systems Manager (SSM) と Ansible は、サーバーの管理や自動化に関して似たような機能を提供しますが、いくつかの重要な違いもあります。以下に、両者の主な特徴と相違点を整理しました。
相違点
特徴 | AWS Systems Manager (SSM) | Ansible |
実行環境 | AWS 環境に特化しており、AWS リソースの管理を目的としたサービス。 | オープンソースであり、AWS に限らずオンプレミスや他のクラウド環境でも利用可能。 |
エージェント/プロトコル | SSM エージェントをインスタンスにインストールして管理。 | SSH や WinRM を使用し、エージェントが不要(エージェントのインストールも可能)。 |
AWS との統合 | AWS の各種サービス(EC2、RDS、S3、IAM など)と深く統合されている。 | AWS サービスとも統合可能だが、追加設定が必要。 |
管理範囲 | AWS 上のリソースを中心に、ハイブリッドクラウドやオンプレミスもサポート。 | オンプレミス、クラウド、ハイブリッド環境全てに対応。 |
操作の複雑さ | AWS の管理コンソールで操作が可能で、グラフィカルで直感的。 | Playbook(YAML形式)の記述が必要で、スクリプトの記述に慣れが必要。 |
コスト | AWS サービスは使用量に応じた料金が発生。 | Ansible はオープンソースで無料。ただし、企業向けサポートの Red Hat Ansible Tower は有料。 |
パッチ管理 | AWS の Patch Manager 機能で、パッチ管理を自動化し、レポートを作成可能。 | Playbook で自動化できるが、補 patch 管理に関しては自分で設定する必要がある。 |
権限管理 | IAM(Identity and Access Management)を使用して、細かい権限設定が可能。 | 主にホストの管理と Ansible Vault を使って秘密情報を管理するが、権限管理は自分で行う必要がある。 |

Systems Managerの機能群
カテゴリ | 機能名 | 説明 |
ノード管理 | Fleet Manager | EC2インスタンスやオンプレミスサーバーの管理 |
運用管理 | Explorer | インスタンスやリソースの探索・監視 |
ㅤ | OpsCenter | インシデントや問題解決の管理ツール |
ㅤ | Incident Manager | インシデントの追跡・解決 |
変更管理 | Change Manager | 変更の承認と実施の管理 |
ㅤ | Change Calendar | 変更作業のスケジュール管理 |
コンプライアンス管理 | Compliance | リソースのコンプライアンス遵守状況の管理 |
自動化 | Automation | 定期的なタスクや作業の自動化 |
インベントリ管理 | Inventory | リソースや構成情報の管理 |
ハイブリッド管理 | Hybrid Activations | ハイブリッド環境(オンプレミス+クラウド)の管理 |
メンテナンス管理 | Maintenance Windows | メンテナンス作業のスケジュール管理 |
セッション管理 | Session Manager | シェルやリモートセッションの管理 |
コマンド実行 | Run Command | 複数のインスタンスへのコマンド実行 |
状態管理 | State Manager | インスタンスの状態を管理、変更を追跡 |
アプリケーション管理 | Patch Manager | パッチの適用と管理 |
ㅤ | Application Manager | アプリケーションのデプロイと管理 |
ㅤ | Distributor | アプリケーションの配布 |
ㅤ | AppConfig | アプリケーション設定の管理 |
ㅤ | Parameter Store | 構成データの管理 |
Amazon Inspector
- 主な機能:
- セキュリティ脆弱性のスキャン。
- パッチ適用漏れの検出。
- 用途: 脆弱性の検出に特化しており、適用プロセス自体は実行しない。
Amazon QuickSight
- 主な機能:
- データの可視化とレポート作成。
- パッチ適用状況のカスタムレポート作成に利用可能。
Amazon EventBridge
- 主な機能:
- イベントルールに基づいて自動アクションを実行。
- パッチスケジュールを自動化可能。
4. パッチ管理ソリューションの選択基準
- 一元管理: 複数の環境(オンプレミス+クラウド)を統一的に管理できること。
- 自動化: 定期的なパッチ適用プロセスを自動化し、手動作業を削減すること。
- レポート機能: コンプライアンス監査や経営報告のためのレポート作成が可能であること。
- 統合性: 他のAWSサービスやツールとシームレスに連携できること。
5. AWSを活用したパッチ管理の利点
- スケーラビリティ: サーバーの増減に応じた柔軟な管理が可能。
- コスト効率: 必要なリソースのみを使用し、無駄を抑える。
- セキュリティ強化: クラウド環境における最新のベストプラクティスを活用。
AWSを使用したパッチ管理は、効率的でセキュアなIT運用を実現するための鍵となります。適切なツールの選択と運用計画が、成功の要因となります。
実践
参照元
事前準備
このセクションでは、クラウドフォーメーションを使用して事前準備を行い、必要なリソースを自動で作成する手順を説明しています。以下に簡潔に整理します。
- 事前準備の目的: EC2インスタンス構築に必要なネットワークリソースや設定をクラウドフォーメーションで一括作成。
- クラウドフォーメーションの概要: リソース作成のためのテンプレートを使用し、EC2やVPCなどをプロビジョニングするサービス。
- 手順:
- AWSマネジメントコンソールで「クラウドフォーメーション」を開く。
- 「スタックの作成」からテンプレートファイルをアップロード。
- ダウンロードしたJSONファイルを指定し、スタック名を入力(例: h4bスタック)。
- オプション設定なしで次へ進み、設定内容を確認後、スタック作成を実行。
- 進行状況: スタック作成に数分かかるため、進行状況を確認し、完了後に「スタック作成完了」の表示がされる。
これで、クラウドフォーメーションを使用した事前準備が完了します。
CloudFormation テンプレート
作業で利用する CloudFormation テンプレートは下記からダウンロードしてください。zip ファイルを解凍して出てくる json ファイルをご利用ください。

EC2の作成
下記のリソースを作成します。
作成されたリソース | 設定・要点 |
IAMロール(SSM-in-EC2) | - 目的: EC2インスタンスが Systems Manager にアクセスできるようにするため。
- ユースケース:EC2
- ポリシー: AmazonSSMManagedInstanceCore ポリシーをアタッチすることにより、必要な権限を付与。- 設定方法: IAMでロールを作成し、そのロールをEC2インスタンスに関連付けます。 |
EC2(SSM-EC2) | - 目的: 管理対象のインスタンスとして Systems Manager を使って管理する。
- SSMエージェント: EC2インスタンスに作成したIAMロールを設定してから、起動します
- サブネット:プライベート
- SG:h4b-ec2-sg |
インターネットゲートウェイ | - 目的: EC2インスタンスがインターネットと通信できるようにするため。- 設定方法: インターネットゲートウェイをVPCにアタッチし、適切なルートテーブルを設定してインターネットへのアクセスを可能にします。 |
Fleet Managerの確認
AWS Systems Manager の Fleet Manager は、EC2インスタンスやオンプレミスサーバーなどのシステムを一元的に管理するためのサービスです。以下は、Fleet Manager の基本機能をまとめた一覧表です。
基本機能 | 説明 |
インスタンス管理 | EC2やオンプレミスサーバーの管理(起動、停止、再起動) |
パフォーマンス監視 | リソース使用率(CPU、メモリ、ディスク)の監視 |
ログ収集 | インスタンスのシステムログを収集、トラブルシューティング |
リモート接続 | インスタンスへのシェルやデスクトップ接続 |
ファイル操作 | ファイルのアップロード、ダウンロード、削除 |
パッチ管理 | ソフトウェアやOSのパッチ適用管理 |
インベントリ管理 | ソフトウェアや設定情報の管理 |
トラブルシューティング | リモートコマンド実行で問題解決支援 |
セキュリティ管理 | セキュリティ設定(アクセス制御、IAMロール管理) |
これらの機能を活用することで、AWSインフラやオンプレミスのシステムを効率的に管理し、トラブルシューティングやパッチ管理、インスタンスの監視などを容易に行うことができます。


Fleet Managerの利用
下記設定を行います
設定項目 | 方法 |
SSM Agentの自動更新設定
SSM Agentを自動で最新バージョンに更新する設定。 | 1. AWS Systems Managerコンソールにアクセス。
2. 自動化を選択し、確認する |
Inventoryの設定
インベントリを有効にし、インスタンスのリソース情報を収集・管理。 | 1. AWS Systems ManagerコンソールでInventoryを選択。
2. インベントリの収集対象を設定し、収集対象のアイテム(OS、アプリケーション等)を選択。
3. 設定後、Fleet Managerにて、情報が収集されるのを確認。 |
State Managerの確認
State Managerでインスタンスの設定や状態を管理・監視。 | 1. AWS Systems ManagerコンソールでState Managerを選択。
2. 既存のオペレーションやルールを確認し、必要な状態が維持されているかをチェック。
3. 監視設定を行い、定期的な状態確認を実施。 |
これらの方法で、Fleet Managerを通じてインスタンスの状態や設定を自動化・効率的に管理できます。

セッションマネージャー

サーバーログイン
セッションマネージャーを使用して、サーバにログインします。

サーバー操作ログの出力設定
操作ログをS3やcloud Watchに保存する設定を行います。




EC2 に また CloudWatchLogsFullAccessの権限を追加して、操作ログの転送が有効になります。
これで、

操作ログがWatchにリアルタイム転送

RUN コマンド
1. AWS Systems Manager (SSM) にアクセス
- AWS Management Consoleにログインし、「Systems Manager」を検索して選択します。
2. Run Commandの使用
- 左側のメニューで「Run Command」をクリックします。
- 「Run a command」ボタンをクリックします。
3. コマンドの設定
- Command document: 「AWS-RunShellScript」を選択します。このドキュメントは、EC2インスタンス上でシェルスクリプトを実行するために使います。
- Command parameters: 以下のように設定します:
- Commands: 実行したいシェルコマンド(例:
echo "Hello, World!") - Execution timeout: コマンドの実行時間のタイムアウトを設定(例:60秒)
4. ターゲットインスタンスの選択
- Targetsセクションで、コマンドを実行するEC2インスタンスを選択します。対象となるインスタンスにSSMエージェントがインストールされ、必要なIAMロールが付与されていることを確認してください。
5. コマンドの実行
- 「Run」ボタンをクリックして、コマンドを実行します。
6. 実行結果の確認
- 実行が完了したら、Command outputセクションに実行結果が表示されます。
例: 「echo」コマンドを実行
- Commands:
- このコマンドを実行すると、選択したインスタンスで「Hello, World!」と表示されます。

まとめ
「Run Command」を使用すると、EC2インスタンスにSSHで接続せずにコマンドを実行できるため、リモートでの管理が簡単に行えます。特に、セキュリティやアクセス制御が必要な場合に有効です。

一問道場
会社はサーバーのパッチ適用プロセスを実装する必要があります。オンプレミスのサーバーとAmazon EC2インスタンスでは、さまざまなツールを使用してパッチ適用を行っています。
経営陣は、すべてのサーバーとインスタンスのパッチ状況を1つのレポートで確認できる仕組みを求めています。
ソリューションアーキテクトが取るべきアクションは次のうちどれですか?
選択肢
A.
- AWS Systems Manager を使用してオンプレミスサーバーとEC2インスタンスのパッチを管理する。
- Systems Manager を使用してパッチコンプライアンスレポートを生成する。
B.
- AWS OpsWorks を使用してオンプレミスサーバーとEC2インスタンスのパッチを管理する。
- Amazon QuickSight をOpsWorksと統合してパッチコンプライアンスレポートを生成する。
C.
- Amazon EventBridge ルールを使用してAWS Systems Managerのパッチ修復ジョブをスケジュールし、パッチを適用する。
- Amazon Inspector を使用してパッチコンプライアンスレポートを生成する。
D.
- AWS OpsWorks を使用してオンプレミスサーバーとEC2インスタンスのパッチを管理する。
- AWS X-Ray を使用してパッチ状況をAWS Systems Manager OpsCenterに投稿し、パッチコンプライアンスレポートを生成する。
014-Auto Scalingライフサイクルフック
理論

Amazon EC2、Auto Scaling、S3に関する基礎知識と関連技術の解説
1. Amazon EC2
Amazon EC2は、クラウド上で仮想サーバーを提供するサービスです。ユーザーは必要に応じてインスタンスを作成し、アプリケーションを実行することができます。
- 特徴:
- 可変性: インスタンスを柔軟に増減可能。
- 拡張性: 自動スケーリングで需要に応じた対応が可能。
- ログ管理: システムログやアプリケーションログを生成。
2. Amazon S3
Amazon S3は、安全で耐久性のあるクラウドストレージを提供します。ログファイルのバックアップやアーカイブ、集中管理に利用されます。
- 用途:
- ログデータの保存と分析。
- アプリケーション間でのデータ共有。
- 自動化されたバックアップシステムの構築。
3. Auto Scaling
Auto Scalingは、EC2インスタンスを需要に応じて自動的にスケールイン・スケールアウトする機能を提供します。
- ライフサイクル:
- スケールアウト (増加): 負荷が高まった場合にインスタンスを追加。
- スケールイン (減少): 負荷が低下した場合にインスタンスを削除。
4. Auto Scalingライフサイクルフック
ライフサイクルフックは、インスタンスの状態遷移中にカスタムアクションを実行できる機能です。
- 例:
- インスタンス終了前にログをS3にアップロード。
- 起動後に設定スクリプトを実行。
- 主な状態遷移:
Pending -> InService: 起動プロセス。Terminating -> Terminated: 終了プロセス。
ABANDONアクションの動作
- 概要:
ライフサイクルフックを設定した場合、インスタンスは遷移中の状態 (
Pending:WaitまたはTerminating:Wait) に留まり、指定された処理が完了するのを待ちます。この状態でABANDONアクションを実行すると、以下の動作が行われます。
- 動作内容:
- Auto Scalingはインスタンスの状態遷移を中止します。
- インスタンスが終了プロセス中の場合 (
Terminating:Wait)、そのインスタンスは終了されません。 - スケーリンググループのサイズは調整されないため、期待されるスケールアウトまたはスケールインの動作に影響を与える可能性があります。
具体例: ログ保存処理におけるABANDON
インスタンスが終了する際に、ログデータをS3にコピーする処理が必要な場合、
ABANDONを使用すると次のように機能します。- シナリオ:
- Auto Scalingでインスタンスが終了プロセスに入る。
- ライフサイクルフックでインスタンスを
Terminating:Waitに設定。 - S3にログをアップロードするスクリプトが失敗する。
- ABANDONの活用:
- スクリプトの失敗を検出し、
ABANDONアクションを送信。 - インスタンスの終了を防ぎ、手動でログを回収したり修正を行う猶予を得る。
注意点
- スケーリンググループの整合性:
ABANDONを使用すると、スケーリンググループのインスタンス数が期待する状態と異なる場合があるため、適切に管理する必要があります。
- 通常の終了との違い:
通常は
CONTINUEアクションを送信して、スケーリングプロセスを再開させますが、ABANDONはその代わりにインスタンスの遷移を停止します。
5. AWS Systems Manager
AWS Systems Managerは、クラウド環境やオンプレミス環境の管理を簡素化するツールセットです。特にスクリプト実行やタスクの自動化で役立ちます。
- 機能:
- Run Command: スクリプトやコマンドをインスタンスで実行。
- Automation: 定型的なタスクを自動化。
- セッション管理: リアルタイムでインスタンスに接続。
6. Amazon EventBridge
EventBridgeはAWS内外のサービスイベントをトリガーとして活用することができます。
- 特徴:
- 自動化されたイベント駆動型アクションを実行。
- AWSサービスとシームレスに統合。
- インスタンスの終了やスケーリングイベントを検知。
7. システム構築の例
以下は、Auto Scalingグループ内でのEC2インスタンス終了時にログを確実にS3に保存するための一例です。
- ライフサイクルフックを設定:
- インスタンスの終了時に処理を遅延させる。
- 遷移中 (
Terminating:Wait) の状態でログ保存処理を実行。
- EventBridgeルールを設定:
- インスタンス終了イベントを検知。
- Lambda関数やSystems Managerのコマンド実行をトリガー。
- AWS Systems Managerでログをコピー:
- EC2インスタンス内のログファイルをS3にアップロードするスクリプトを作成。
- ライフサイクルフックからこの処理を呼び出し、完了後にインスタンスを終了。
8. メリットとベストプラクティス
- 信頼性向上: インスタンス終了時のデータ喪失防止。
- スケーリングへの影響最小化: 処理完了後に速やかに終了。
- コスト最適化: インスタンスの無駄なリソース消費を抑制。
これらの知識を基に、スケーラブルで信頼性の高いログ管理システムを構築できます。A
実践


アーキテクチャの概要
- 目的:
EC2 Auto Scalingにおいて、インスタンスがターミネートされる際に、重要なログデータを退避させる仕組みを構築する。
- 主な要素:
- EC2 Auto Scaling: 動的にインスタンスをスケールさせる。
- ライフサイクルフック: インスタンスの終了プロセス中に処理を挟む。
- ログ退避ストレージ: Amazon S3や他のストレージサービス。
- 通知と実行管理: Amazon SNS、AWS Lambda、またはStep Functionsを利用。

今回のアーキテクチャのフロー
- ライフサイクルフックの設定
- Auto Scalingグループにライフサイクルフックを設定。
- インスタンスの終了時にイベントが発生し、EventBridgeに通知。
- EventBridgeによるトリガー
- ライフサイクルフックのイベントを受けて、EventBridgeがLambda関数をトリガー。
- SSMドキュメントの実行
- Lambda関数が、事前に準備されたSSMドキュメントを利用して、対象のEC2インスタンスにRun Commandを実行。
- インスタンス内の必要なログを収集し、S3へ転送。
- ログ退避
- インスタンスがターミネートされる前に、退避が必要なログデータをS3に安全に保存。
構成要素
- Auto Scalingグループ
インスタンスの動的なスケーリングと管理。
- ライフサイクルフック
インスタンス終了時の「Terminating:Wait」状態で退避処理を実行。
- EventBridge
ライフサイクルフックのイベントを監視し、Lambda関数をトリガー。
- AWS Lambda
ログ退避の実行管理。SSMドキュメントを実行。
- Amazon S3
退避されたログデータの保存先。
- AWS Systems Manager (SSM)
Run Commandを利用してインスタンス内の操作を実行。
メリット
- 自動化されたログ退避プロセスにより、手作業を削減。
- 重要なログを確実に保存し、可用性とセキュリティを向上。
- EventBridgeとLambdaを活用した柔軟な設計。
注意点
- ライフサイクルフックでの処理がタイムアウトしないように、十分な時間を設定。
- S3のバケットポリシーやIAMロールの権限設定を適切に構成。
- Lambda関数のエラー処理と監視を実装。
ハンズオン
ログ格納用S3バケットの準備
まずは下記構成図の赤点線部分のS3バケットを作っていきます。

ログ格納用のS3バケットはデフォルトの設定で問題ありません。次の工程で「バケット名」を使うのでバケット名は控えておいてください。

SSM Documentの準備
次に、下記構成図の赤点線部分のSSM Documentを作成していきます。

Systems Managerのダッシュボードから「共有リソース」-「ドキュメント」を選択し「Create document」-「Command or Session」を選択します。

任意の名前を入力し、ターゲットオプションに「/AWS::EC2::Instance」を選択、ドキュメントタイプに「コマンドドキュメント」を選択します。

コンテンツエリアで「YAML」を選択し下記のコマンドをコピペします。対象のログは実際の環境で対象としたいログファイル/ログファイルのパスに置き換えてください。また、「バケット名」には前工程で作成したログ格納用S3バケットの名前を指定します。

SSM Documentが作成されたことを確認します。

Lambdaの準備
次に、下記構成図の赤点線部分のLambda関数を作成していきます。

コードはPython3.9で作成しています。コード自体はシンプルでEventBridge経由で受け取ったイベントのデータからインスタンスIDを抽出して、Run Command実行時の対象EC2として指定をしています。

Lambda関数からSSM Documentを叩くため、Lambda関数にアタッチされているロールに必要な権限を付与しておきます。「設定」-「アクセス権限」からアタッチされているロールを選択します。
今回は
AmazonSSMFullAccessを割り当てておきます。
Lambda関数の準備が完了しました。
EventBridgeの準備
次に、下記構成図の赤点線部分赤点線部分のEventBridgeのルールを作成していきます。

EventBridgeのダッシュボードから「ルールを作成」を選択します。

任意の名前と説明を入力します。

パターン定義で「イベントパターン」-「カスタムパターン」を選択し、イベントパターンに下記のパターンをコピペし「保存」します。

ターゲットに「Lambda関数」を選択し、前の工程で作成したLambda関数を指定します。

その他はデフォルトで作成します。
Auto Scalingグループを作成
まずは下記構成図の黒枠部分のをAuto Scaling作っていきます。

Auto Scalingグループを作成するには、まずインスタンステンプレートを作成する必要があります。その後、Auto Scalingグループを作成して、スケーリングポリシーやターゲット設定を行います。以下にその手順を詳細に説明します。
1. EC2ダッシュボードに移動
- AWS Management Consoleにログインし、EC2ダッシュボードに移動します。
- 左側のナビゲーションペインから「Auto Scaling Groups」を選択します。
2. Auto Scalingグループの作成
- 「Create Auto Scaling group」ボタンをクリックします。
3. インスタンステンプレートの作成
Auto Scalingグループに使用するインスタンステンプレートを作成します。このテンプレートは、Auto Scalingグループがインスタンスを起動する際に使用する設定を定義します。
- 左側のメニューから「Launch Templates」を選択し、「Create launch template」をクリックします。
- Launch Template Name(例:
my-auto-scaling-template)を入力します。
- AMI (Amazon Machine Image)を選択します。例えば、Amazon Linux 2023など、アプリケーションに適したAMIを選びます。
- インスタンスタイプ(例:
t2.micro)を選択します。
- その他の設定(ネットワーク、セキュリティグループ、IAMロールなど)を設定します。これらは、アプリケーションに必要なアクセス権やネットワークの設定を反映させるために重要です。
- ユーザーデータ - オプション

4. Auto Scalingグループを作成
インスタンステンプレートが作成されたら、これを使用してAuto Scalingグループを作成します。
- 「Create Auto Scaling group」ボタンをクリックし、作成したインスタンステンプレートを選択します。
- Auto Scalingグループ名を入力します(例:
my-auto-scaling-group)。
- ターゲットグループとして、ALB(Application Load Balancer)を選択します。ALBは、トラフィックをAuto Scalingグループ内のインスタンスに分散します。
- 新しいロードバランサーにアタッチすると設定します。新しいロードバランサーのスキームはInternet-facingに設定


- 新しいターゲットグループ名と設定します。

5. Auto Scalingポリシーの設定
Auto Scalingの設定を行います。これには、インスタンスの最小数、最大数、スケーリングのポリシーを含みます。
- 最小インスタンス数と最大インスタンス数を設定します。例えば、最小インスタンス数を
0、最大インスタンス数を1に設定することができます。

- スケーリングポリシーを設定します。これには、CPU使用率やネットワークトラフィックなどに基づいてインスタンス数をスケーリングするルールを作成します。
6. 必要なネットワーク設定を行う
Auto Scalingグループが使用するVPC(仮想プライベートクラウド)とサブネットを選択します。これにより、インスタンスが配置されるネットワーク環境が決定されます。
- VPCとサブネットを選択します。通常は、ALBと同じVPC内のサブネットを選ぶことが一般的です。
- 必要に応じて、セキュリティグループやIAMロールを設定します。
7. Auto Scalingグループの作成
設定が完了したら、「Create Auto Scaling group」ボタンをクリックして、Auto Scalingグループの作成を完了します。

これで、Auto Scalingグループが作成され、インスタンステンプレートに基づいて自動的にインスタンスが起動されるようになります。また、ALBと連携してトラフィックを効率的に分散させることができます。
8. ALBのURLでアクセスしてみる

ライフサイクルフックの設定
最後に、下記構成図の赤点線部分のライフサイクルフックの設定を実施していきます。

EC2のダッシュボードから「Auto Scalling Groups」を選択し、対象となるAuto Scallingグループ名を選択します。

「インスタンス管理」タブを選択し「ライフサイクルフックを作成」を選択します。

上記部分のパラメータについて補足をしておきます。
- ライフサイクル移行
ライフサイクルフックには「起動ライフサイクルフック」と「終了ライフサイクルフック」の2種類があり、今回は「終了ライフサイクルフック(インスタンス終了)」を使用してインスタンスのターミネートを遅らせ、その間にログの退避をする構成としています。もう一方の「起動ライフサイクルフック」を使用するケースとしては、AutoScallingの起動設定やベースAMIに組み込めない設定や作業をスケールアウトのタイミングに行うケースなどが考えられます。
- ハートビートタイムアウト
EC2インスタンスの起動またはターミネートを遅らせる時間を「ハートビートタイムアウト」の時間として設定します。この「ハートビートタイムアウト」の秒数は設計が必要になる部分なのですが、必要な作業が完了する十分な時間を割り当てておくと良いでしょう。「ハートビートタイムアウト」は下図の青色部分を指し、起動またはターミネートの「Wait」として設定されることとなります。
最後にIAM権限を適切に修正、Autoscalingのキャパシティーを2→1に調整することで、テストする
要素 | 設定が必要なIAM権限 |
AutoScaling | 特に設定なし |
EventBridge | 検出を開始 |
Lambda | SSMManagedInstanceCore ssm:SendCommand |
SSM Run Command | 特になし |
S3 | 特になし |
EC2 | SSMManagedInstanceCore s3:PutObject |

一問道場
ある企業が、複数のAmazon EC2インスタンスをAuto Scalingグループで運用しており、これらのインスタンスはApplication Load Balancerの背後で実行されています。アプリケーションの負荷は時間帯によって変動し、EC2インスタンスは定期的にスケールイン・スケールアウトしています。ログファイルは15分ごとに中央のAmazon S3バケットにコピーされていますが、セキュリティチームは、終了したEC2インスタンスからログファイルが欠落していることに気付きました。
終了したEC2インスタンスからログファイルを確実にS3バケットにコピーするためには、どのアクションが必要ですか?
A.
- ログファイルをAmazon S3にコピーするスクリプトを作成し、EC2インスタンスに保存する
- Auto ScalingライフサイクルフックとAmazon EventBridgeルールを作成して、Auto Scalingグループのライフサイクルイベントを検出
autoscaling:EC2_INSTANCE_TERMINATINGトランジションでAWS Lambda関数を呼び出し、Auto ScalingグループにABANDONを送信してインスタンスの終了を防止
- スクリプトを実行してログファイルをS3にコピーし、AWS SDKを使ってインスタンスを終了する
B.
- ログファイルをS3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成
- Auto ScalingライフサイクルフックとAmazon EventBridgeルールを作成して、ライフサイクルイベントを検出
autoscaling:EC2_INSTANCE_TERMINATINGトランジションでAWS Lambda関数を呼び出し、AWS Systems ManagerのSendCommand操作でスクリプトを実行
- ログファイルをコピーし、Auto ScalingグループにCONTINUEを送信してインスタンスを終了
C.
- ログ配信レートを5分ごとに変更
- ログファイルをS3にコピーするスクリプトを作成し、EC2インスタンスのユーザーデータに追加
- EC2インスタンス終了を検出するAmazon EventBridgeルールを作成
- EventBridgeルールからAWS Lambda関数を呼び出し、AWS CLIを使ってユーザーデータスクリプトを実行してログファイルをコピーし、インスタンスを終了
D.
- ログファイルをS3にコピーするスクリプトを含むAWS Systems Managerドキュメントを作成
- Auto Scalingライフサイクルフックを作成し、メッセージをAmazon SNSに送信
- SNS通知をトリガーに、AWS Systems ManagerのSendCommand操作でスクリプトを実行
- ログファイルをコピーし、Auto ScalingグループにABANDONを送信してインスタンスを終了
解説
この問題は、Amazon EC2インスタンスがAuto Scalingグループの一部として稼働している状況で、インスタンス終了時にログファイルがS3にコピーされないという問題に関するものです。問題の目的は、EC2インスタンスが終了する際にもログファイルを確実にS3に保存するための解決策を選択することです。
以下は、各選択肢の詳細な解説です。
A. スクリプトを作成してEC2インスタンスからログをS3にコピーし、Auto ScalingライフサイクルフックとEventBridgeを使用して処理を管理する
- 問題点: この方法では、インスタンスが終了する際に「ABANDON」アクションを使ってインスタンスの終了を防ぐことが前提です。しかし、インスタンスの終了を防ぐことは、リソースの過剰使用やスケールインの遅延を引き起こし、最適な解決策ではありません。
- 理由: インスタンスの終了を待ってから作業を行うと、他のスケーリング操作に影響を与える可能性があります。
B. AWS Systems Managerを使用してスクリプトを実行し、ログファイルをS3にコピーする
- 解説: Systems Managerの「SendCommand」を使用して、EC2インスタンスでスクリプトを実行し、ログファイルをS3にコピーします。ライフサイクルフックを使用してインスタンスが終了する前に処理を行い、終了後には「CONTINUE」アクションを使って正常に終了させます。
- 理由: Systems Managerを使うことで、インスタンスの終了を中断することなく、ログファイルを確実にバックアップできます。この方法は、AWSの推奨される実装方法です【16†source】。
C. ユーザーデータスクリプトを使い、インスタンス終了時にログをコピーする
- 解説: ユーザーデータスクリプトは、インスタンス起動時に自動的に実行されるスクリプトです。この方法では、インスタンスが終了する際にイベントを検出して処理を行いますが、ログを確実にコピーするための管理が難しくなる可能性があります。
- 理由: ユーザーデータはインスタンスの起動時に処理を行うため、終了時にログをバックアップするためには追加の仕組みが必要となります【16†source】。
D. SNSを使って通知を送信し、Systems Managerでログをコピーする
- 解説: SNS通知を使用して、インスタンス終了時に必要な作業をトリガーし、その後AWS Systems Managerを使ってログをコピーします。これにより、通知を受け取って処理を実行できますが、「ABANDON」を使用してインスタンスを中断する必要があるため、スケーリングに影響を与える可能性があります。
- 理由: SNSを利用する方法は、設定が少し複雑で、インスタンスの終了を中断する必要があるため、最適な方法とは言えません【15†source】。
まとめ
正しい解決策は B の「AWS Systems Managerを使用したスクリプトの実行」です。この方法は、インスタンスの終了をスムーズに行いながら、確実にログをS3にバックアップするための最適なアプローチです。
015-アカウント関のプライベートホストゾーンを名前解決
理論
Amazon Route 53のプライベートホストゾーンとVPC関連付けに関する知識
1. プライベートホストゾーン(Private Hosted Zone)
プライベートホストゾーンは、AWSのRoute 53におけるDNS管理機能の一つで、特定のVPC内でのみ解決されるDNSレコードを管理します。インターネット上ではアクセスできず、プライベートネットワーク内のリソース同士の名前解決を行うために使用されます。
- VPCとの関連付け: プライベートホストゾーンは、特定のVPCと関連付けて使用します。この設定により、そのVPC内のインスタンスやリソースがDNS名を解決できるようになります。また、他のVPCと接続する場合や複数のVPCで利用する場合は、関連付けの手続きを行う必要があります。
2. VPC間でのDNS解決
異なるVPC間でDNS解決を行いたい場合、VPC PeeringやTransit Gatewayを使ってVPC同士を接続し、その後、DNS解決機能を有効化する必要があります。VPC Peeringを利用する場合、DNS解決を有効にする設定が必要で、これによりVPC間で名前解決を行うことができます。
3. AWS CLIによる設定
AWSマネジメントコンソールだけでは、VPCとプライベートホストゾーンを異なるアカウント間で関連付けることはできません。CLIやSDKを使用して、VPCの関連付けの承認や実際の設定を行う必要があります。
- 関連付けの承認: アカウントAのVPCからアカウントBのVPCに対してプライベートホストゾーンの関連付けを許可する承認プロセスを行います。この承認を通じて、アカウントBのVPCがアカウントAのプライベートホストゾーンのレコードを解決できるようになります。
4. アカウント間での設定
AWSでは、通常、プライベートホストゾーンを同一アカウント内のVPCに関連付けることができますが、異なるアカウント間で関連付けを行う場合、明示的な承認が必要です。これにより、異なるアカウント間でDNS解決を行うためのアクセス権限を付与できます。
まとめ
この問題に関連する本質的な知識は、Route 53のプライベートホストゾーンをVPC間で適切に管理する方法に関するものです。特に、異なるアカウント間でプライベートホストゾーンを関連付けるためには、AWS CLIやSDKを利用した設定が必要であり、VPC PeeringやTransit Gatewayを使ったDNS解決の設定も考慮する必要があります。このような設定を行うことで、異なるVPC間での名前解決を実現することができます。
実践
参照元:


別アカウントのプライベートホストゾーンを名前解決:はじめに
今回はアカウントBで作成したプライベートホストゾーンのDNSレコードを、アカウントAから名前解決できるように設定します。
プライベートホストゾーンとは
- 設定したVPC内でのみ使用できるプライベート用のドメイン
- インターネットに公開するパブリックドメインとは使用目的が異なる
- [VPCの関連付け] を行うことで、別のAWSアカウントからも名前解決できる
別アカウントのプライベートホストゾーンを名前解決するための準備

事前準備として、アカウントAとアカウントBでVPCとEC2を作成します。
2つのアカウントのVPC DNS設定を有効化
アカウントAとアカウントBのVPC画面で、以下のDNS設定が [有効] になっていることを確認します。
2つのアカウントのVPC DNS設定を有効化
アカウントAとアカウントBのVPC画面で、以下のDNS設定が [有効] になっていることを確認します。
- DNSホスト名
- DNS解決
もし無効になっている場合は、対象のVPCを選択 -> 右上の [アクション] -> [DNSホスト名を編集] または [DNS解決を編集] からそれぞれ有効化します。
2つのアカウントでEC2を用意
プライベートホストゾーンへのVPC関連付けは、マネジメントコンソールからは設定できません。
AWS CLIやAWS SDKなどを使用する必要がありますが、今回はAWS CLIを使用します。
アカウントAとアカウントBでEC2 (Amazon Linux 2023) をt2.microで作成、パブリックサブネットに配置しパブリックIPアドレスを付与します。
下記の設定項目に基づいてEC2を作成してください。
設定項目 | アカウントA | アカウントB |
所属VPC | プライベートホストゾーンを関連付けるVPC VPC-A | EC2が配置され、プライベートホストゾーンを利用するVPC VPC-B |
EC2インスタンス | Amazon Linux 2023(t2.micro、パブリックサブネット、パブリックIPアドレス付与)EC2-A | Amazon Linux 2023(t2.micro、パブリックサブネット、パブリックIPアドレス付与)EC2-B |
サブネット | パブリックサブネット | パブリックサブネット |
2つのアカウントのEC2にIAMロールを設定
IAMポリシーはRoute 53の
CreateVPCAssociationAuthorizationなどが必要です。今回はテスト目的のため、上記権限が含まれるIAMポリシー
PowerUserAccessをIAMロールに付与し、それぞれのEC2に設定します。プライベートホストゾーン作成

アカウントBでプライベートホストゾーンとAレコードを作成します。
1. アカウントBのEC2 プライベートIPアドレスをメモ
アカウントBのEC2画面から、EC2に設定されているプライベートIPアドレスをテキストエディタなどにコピペしておきます。
2. アカウントBでプライベートホストゾーンを作成
アカウントBのRoute 53画面でプライベートホストゾーン を作成します。
[ホストゾーン] -> [ホストゾーンの作成] をクリック。

[ホストゾーン設定] は以下のとおり設定。今回はテスト目的なのでドメイン名は [example.com] としました。
- ドメイン名:example.com
- 説明:(オプション)今回は設定しない
- タイプ:プライベートホストゾーン

[ホストゾーンに関連付けるVPC] は以下のとおり設定し、[ホストゾーンの作成] をクリック。
- リージョン:アジアパシフィック (東京)
- VPC ID:アカウントB側のVPC
- タグ:(オプション)今回は設定しない

3. プライベートホストゾーンにAレコードを作成
アカウントBのEC2 プライベートIPアドレスに紐づくAレコードを作成します。
[レコードを作成] をクリック。

以下のとおり設定し [レコードを作成] をクリックします。[TTL] と [ルーティングポリシー] はデフォルトのままで大丈夫です。
- レコード名:ec2-account-b
- レコードタイプ:A - IPv4アドレスと一部のAWSリソースに・・略
- 値:前の手順でメモしたアカウントBのEC2プライベートIPアドレス

Aレコードを作成できました。

4. アカウントB側のホストゾーンIDを確認
[ホストゾーンの詳細] をクリックし、[ホストゾーン ID] をテキストエディタなどにコピペしておきます。このあとのAWS CLI実行時に使用します。
ちなみに、[関連付けられた VPC] にはアカウントBのVPC IDだけが表示されていますが、本手順を進めるとアカウントAのVPC IDも追加されます。

5. アカウントBで名前解決できることを確認
アカウントBのEC2 (Amazon Linux 2)にSSH接続します。
アカウントBのEC2で以下を実行し、作成したプライベートホストゾーンのレコードが名前解決できることを確認します。
名前解決に失敗する場合は、数分待ったあと再度確認します。DNSレコードが浸透(伝播)されるまで少し時間がかかるためです。
名前空間 (example.com など) が重複する場合、パブリックDNSよりプライベートDNSが優先的に名前解決されます。
プライベートホストゾーンへのVPC関連付け (VPC associate)

1. アカウントA側のVPC IDを確認
302263050396
アカウントAのVPC画面から、VPC IDをテキストエディタなどにコピペしておきます。このあとのAWS CLI実行時に使用します。

2. アカウントB側でアカウントAのVPCからの関連付けを許可
Amazon Route 53 と AWS CLI を使用して、VPC(仮想プライベートクラウド)とプライベートホストゾーンの関連付けを認可する手順を実行しています。この操作により、特定の VPC を Route 53 のプライベートホストゾーンに関連付けることができるようになります。
アカウントBのプライベートホストゾーンに対して、アカウントAのVPCからの関連付けを許可します。
アカウントBのEC2で以下のcreate-vpc-association-authorization を実行します。
少し混乱しやすいのですが、プライベート ホストゾーンIDはアカウントB側で、VPC IDはアカウントA側である点に注意しましょう。


3. アカウントA側からアカウントBのプライベートホストゾーンへのVPC関連付け
アカウントAから、アカウントBのプライベートホストゾーンに対してVPC関連付けを行います。
アカウントAのEC2 (Amazon Linux 2)にSSH接続し、アカウントAのEC2で以下の
associate-vpc-with-hosted-zone を実行します。出力例:コマンド実行直後は [Status] が [PENDING] となっている
数秒経過後に再度
associate-vpc-with-hosted-zone を実行してみます。通常であれば以下が表示されますが、「既にVPC関連付けが済んでいる」という内容なので、これは正しい結果です。(以下は見やすいように改行しています)
アカウントBのRoute53 画面を更新すると、[関連付けられたVPC] にアカウントAの VPC ID が追加されています。

4. VPC関連付けの許可を削除
手順3のVPC関連付けが完了したあとは、手順2で実施した「VPC関連付けの許可」を削除しておきます。同じVPC IDからのVPC関連付けの再実行を防ぐためです。
例えば、今後アカウントBのプライベートホストゾーンで他アカウントからのVPC関連付け削除したとします。その場合は上記の「VPC関連付けの許可」を削除しておかないと、アカウントBの同じVPC IDから再度 VPC関連付けができてしまいます。
別の言い方をすると、プライベートホストゾーンを持つAWSアカウントが許可した時だけ、他のアカウントからのVPC関連付けできるようにするということですね。
- VPC関連付けの許可を削除しても、設定済みのVPC関連付けには影響しません。
- 今後、プライベートホストゾーンとアカウントAのこのVPCを再度関連付けたい場合は、手順 2 および 3 を繰り返します。
アカウントBのEC2で以下の
list-vpc-association-authorizations を実行します。出力例:[VPCs] にVPC関連付けを許可しているVPCが表示される
アカウントBのEC2で以下の
delete-vpc-association-authorization を実行します。コマンドが成功した場合は、結果は何も出力されません。
アカウントBのEC2で以下の
list-vpc-association-authorizations を実行します。出力例:[VPCs] が空になった
5. アカウントAで名前解決できることを確認
アカウントAのEC2で以下を実行し、作成したプライベートホストゾーンのレコードが名前解決できることを確認します。
名前解決に失敗する場合は、数分待ったあと再度確認します。
他アカウントのプライベートホストゾーンを名前解決:まとめ
別アカウントで作成したプライベートホストゾーンのレコードを、DNSで名前解決する手順をご紹介しました。
VPC関連付けのコマンドで、VPC IDの指定が少し混乱しやすいので、手順をよく確認しながらAWS CLIを実行していただければと思います。
最後に、テスト目的で作成したプライベートホストゾーンは忘れずに削除しましょう。
一問道場
ある企業が複数のAWSアカウントを使用しています。
- DNSレコードは、Account A の Amazon Route 53 プライベートホストゾーンに保存されています。
- アプリケーションとデータベースは、Account B に配置されています。
ソリューションアーキテクトは、新しい VPC に 2層アプリケーションをデプロイする予定です。
設定を簡素化するため、Account A の Route 53 プライベートホストゾーンに
db.example.com の CNAME レコードセットを作成し、Amazon RDS エンドポイントを登録しました。しかし、デプロイ時にアプリケーションが起動に失敗しました。
トラブルシューティングの結果、
db.example.com が Amazon EC2 インスタンス上で解決できないことが判明しました。ソリューションアーキテクトは、Route 53 のレコードセットが正しく作成されていることを確認済みです。
この問題を解決するために、ソリューションアーキテクトが取るべき手順はどれですか?
(2つ選択)
選択肢
A.
データベースを新しい VPC の別の EC2 インスタンスにデプロイし、そのインスタンスのプライベート IP アドレス用のレコードセットをプライベートホストゾーンに作成する。
B.
アプリケーション層の EC2 インスタンスに SSH で接続し、RDS エンドポイントの IP アドレスを
/etc/resolv.conf ファイルに追加する。C.
Account A のプライベートホストゾーンを、Account B の新しい VPC と関連付けるための承認を作成する。
D.
Account B で
example.com ドメインのプライベートホストゾーンを作成し、AWS アカウント間で Route 53 のレプリケーションを構成する。E.
Account B の新しい VPC を Account A のホストゾーンに関連付ける。そして、Account A で関連付けの承認を削除する。
どの選択肢を選びますか?
選択肢の解説
A. データベースを新しい VPC の別の EC2 インスタンスにデプロイし、そのインスタンスのプライベート IP アドレス用のレコードセットをプライベートホストゾーンに作成する。
→ 誤り
この手順では、問題の根本原因である VPC 間の DNS 解決を解決できません。Route 53 プライベートホストゾーンの設定に手を加えないため、DNSが解決しない問題が残ります。
B. アプリケーション層の EC2 インスタンスに SSH で接続し、RDS エンドポイントの IP アドレスを
/etc/resolv.conf ファイルに追加する。→ 誤り
/etc/resolv.conf を変更しても、これは手動設定でありスケーラビリティや自動化に欠けます。また、RDS エンドポイントの IP アドレスは動的に変わる可能性があり、これでは管理が非効率的です。根本的な解決策ではありません。C. Account A のプライベートホストゾーンを、Account B の新しい VPC と関連付けるための承認を作成する。
→ 正解
Route 53 プライベートホストゾーンはデフォルトで同一アカウント内の VPC にのみ関連付けられます。他のアカウント(Account B)の VPC からアクセスするには、関連付け承認を作成する必要があります。これにより、Account A のホストゾーンを Account B の VPC から参照できるようになります。
D. Account B で
example.com ドメインのプライベートホストゾーンを作成し、AWS アカウント間で Route 53 のレプリケーションを構成する。→ 誤り
Route 53 プライベートホストゾーンにおいて、AWSアカウント間でのレプリケーションはサポートされていません。この手順は実現不可能です。
E. Account B の新しい VPC を Account A のホストゾーンに関連付ける。そして、Account A で関連付けの承認を削除する。
→ 正解
Account B の VPC を Account A のプライベートホストゾーンに関連付けることは正しい手順です。これにより、Account B の VPC 内で
db.example.com が解決可能になります。関連付けの承認を削除するという手順も、関連付けが有効になった後は不要になるため問題ありません。正解
C と E
解決のポイントは、VPC 間での Route 53 プライベートホストゾーンの利用を正しく設定することです。この問題では、異なる AWS アカウントにまたがる VPC 間で DNS 解決を有効にするための手順が求められています。
016-ビデオをS3+CLFで配信
理論
EC2インスタンス、Auto Scaling、ALB、EFSの理解と最適化
1. Amazon EC2インスタンス
- クラウド上で仮想サーバーを提供
- スケーラビリティと多様なインスタンスタイプをサポート
2. Auto Scaling
- トラフィックに応じてEC2インスタンスの数を自動調整
- コスト効率を最適化し、可用性を向上
3. アプリケーションロードバランサー (ALB)
- HTTP/HTTPSトラフィックを効率的に分散
- 高度なルーティングとセキュリティ機能を提供
4. Amazon EFS
- 複数のEC2インスタンスが同時にアクセスできるスケーラブルなネットワークファイルシステム
- 高い耐障害性と自動スケーリング
5. コンテンツ配信ネットワーク (CDN)
- CloudFrontを使って、エッジロケーションからコンテンツを高速に配信
- 動画や静的コンテンツの配信に最適
6. 動画コンテンツの配信と最適化
- EFSは動画のストレージには不向き
- Amazon S3 と CloudFront の組み合わせが最適
7. コスト効率の最適化
- Auto ScalingとCloudFrontでコスト削減
- 動画コンテンツをEFSからS3に移行し、CloudFrontで配信
Amazon EFSは、主に以下のシナリオに適しています:
EFSが適している配信シナリオ
- アプリケーションデータや設定ファイルの共有 複数のEC2インスタンスが同じデータを共有する必要がある場合に最適。
- コンテンツの共有・アクセス制御 同時にアクセスする複数のインスタンスでファイル共有が必要な場合に適しています。
- 高い耐障害性とスケーラビリティ 高可用性と自動スケーリングが求められるシステムに適しています。
EFSが適していない配信シナリオ
- 大量の静的コンテンツやメディアファイルの配信 メディアファイルには、S3とCloudFrontの方が効率的です。
- 高い配信速度と低遅延が求められる場合 S3とCloudFrontを使うことで、配信速度や低遅延が改善されます。
まとめ
EFSはファイル共有やアプリケーションデータの保存に最適ですが、大量の静的コンテンツやメディアファイルの配信にはS3とCloudFrontが最適です。
実践
EFSに関連したハンズオン


CLFと静的なウェブサイトホスティングに関連したハンズオン
参照元


AWSを使用した静的ウェブサイトのホスティング - ハンズオンガイド
1. 概要
このハンズオンでは、AWSのS3バケットを使用して静的ウェブサイトをホスティングし、その後CloudFrontを経由してコンテンツを配信する方法を紹介します。本記事では、基本的なS3設定とCloudFront設定を手順ごとに解説します。なお、ドメイン取得の手順は含まれていません。
2. 使用するサービス
- Amazon S3 (Simple Storage Service):静的ウェブサイトのホスティングに使用。
- Amazon CloudFront:コンテンツを世界中に配信するためのCDN(コンテンツデリバリーネットワーク)サービス。
3. システム構成
静的なHTMLファイルをAmazon S3バケットに格納し、CloudFrontディストリビューションを作成して、インターネット上でウェブサイトを公開する構成です。
4. ハンズオン手順
4.1. S3バケットの作成
- S3コンソールにログインし、「バケットを作成」をクリック。
- リージョン選択:東京リージョン(
ap-northeast-1)を選択。
- バケット名:一意な名前を選択(例:
my-website-bucket)。バケット名はグローバルで一意でなければならず、命名規則に従う必要があります(3~63文字、使用可能な文字は小文字、数字、ハイフン、ドット)。
- パブリックアクセス設定:静的ウェブサイトを公開するために、パブリックアクセスのブロックを解除します。
- 「バケットを作成」をクリック。
4.2. S3バケットの設定
- バケットを選択し、「プロパティ」タブを開きます。
- 「静的ウェブサイトホスティング」の設定で「有効にする」を選択。
- インデックスドキュメントとして「
index.html」を設定。
- 設定を保存。
4.3. アクセス許可の設定
- バケットポリシーを追加して、公開アクセスを許可します。
- 以下のバケットポリシーを設定します:
(
my-website-bucketは実際のバケット名に置き換えてください。)4.4. HTMLファイルのアップロード
- ローカルでビデオファイルやHTMLファイルをを作成。
- 作成したビデオファイルやHTMLファイルをS3バケットにアップロード。
4.5. 静的ウェブサイトの確認
- S3バケットの「プロパティ」タブで、静的ウェブサイトのエンドポイントURLをコピー。
- ブラウザにそのURLを入力し、
index.htmlが正しく表示されることを確認。
4.6. CloudFrontディストリビューションの作成
- CloudFrontコンソールに移動し、「ディストリビューションを作成」をクリック。
- オリジンドメイン名:S3バケット名を選択。
- *Origin Access Control (OAC)**を選択し、設定を進めます。
- デフォルトルートオブジェクトに「
index.html」を指定。
- 必要な設定を行い、ディストリビューションを作成。
- 作成後、ディストリビューションが有効化されるまで数分間待機。
4.7. CloudFrontからアクセスできるか確認
- CloudFrontディストリビューションが作成されると、ドメイン名が提供されます。
- ブラウザでそのドメイン名を入力し、
index.htmlが表示されることを確認。
5. リソースの削除
作成したリソースが不要になった場合、S3バケットとCloudFrontディストリビューションを削除します。削除しない場合、料金が発生する可能性があります。
このガイドを参考に、AWSで静的ウェブサイトのホスティングを行い、CloudFrontを使ってコンテンツ配信を高速化しましょう!
一問道場
問題:
- 企業は、Amazon EC2インスタンスを使用してWebフリートを展開し、ブログサイトをホストしています。
- 「Webフリート」 は、インターネット上で提供されるWebサービスの運用に必要な複数のサーバー群やリソースを一括で管理する概念を表しています。
- EC2インスタンスは、アプリケーションロードバランサー(ALB)の背後に配置され、自動スケーリンググループに設定されています。
- Webアプリケーションは、すべてのブログコンテンツを Amazon EFS ボリュームに保存しています。
- 最近、ブロガーが投稿にビデオを追加できる機能を追加し、以前の 10倍 のユーザートラフィックが発生しました。
- ピーク時 に、ユーザーがサイトにアクセスしたり、ビデオを視聴しようとした際に バッファリング や タイムアウト の問題が報告されています。
質問:
ユーザーの問題を解決するために、最もコスト効率が良く、スケーラブルな展開方法はどれですか?
選択肢:
A.
Amazon EFSの設定を再構成して、最大I/Oを有効にする
B.
ブログサイトを更新して、インスタンスストアボリュームをストレージに使用し、起動時にサイトコンテンツをボリュームにコピーし、シャットダウン時にAmazon S3にコピーする
C.
Amazon CloudFrontディストリビューションを設定し、ディストリビューションをS3バケットにポイントし、ビデオをEFSからAmazon S3に移行する
D.
すべてのサイトコンテンツに対してAmazon CloudFrontディストリビューションを設定し、ディストリビューションをALBにポイントする
解説:
最もコスト効率が良く、スケーラブルな方法を選ぶには、コンテンツ配信の最適化が重要です。特に、ビデオのような大容量のコンテンツに対して、以下のように負荷分散やキャッシュの活用が有効です:
- 選択肢A はEFSのI/O性能を最大化することを提案しますが、EFS自体は動画などの大容量データの取り扱いには限界があり、スケーラビリティには不十分です。
- 選択肢B はインスタンスストアとS3を利用していますが、データを手動で移行する手間がかかり、スケーラビリティや管理の負担が大きくなります。
- 選択肢C は、動画コンテンツをS3に移行し、CloudFrontで配信する方法です。これにより、動画の配信が高速化し、EFSの負担を減らすことができ、スケーラブルで効率的です。
- 選択肢D は、すべてのコンテンツに対してCloudFrontを使い、ALBを通じて配信する方法です。これにより、全てのコンテンツがキャッシュされて高速に配信され、ピーク時でもスムーズにユーザーにコンテンツを届けることができます。
最も適切な選択肢は
C または D です。特に、動画コンテンツの配信に関しては C が効果的です。
017-Direct Connect Gateway
理論
AIFとは
AWS VIF(Virtual Interface)は、会社側に設置するものです。具体的には、AWS Direct Connectを使用して、企業のオンプレミスネットワーク(例えば、データセンターやオフィス)とAWSを接続するための仮想インターフェースです。
設置場所についての説明
1. 会社側(オンプレミス)の設置
- VIFの管理と設定は、主に企業側のネットワーク機器(ルーターやファイアウォール)で行います。
- 役割: 企業のオンプレミスネットワーク(例えば、データセンターやオフィス)とAWS Direct Connectの接続を確立します。企業側でVIFを作成し、AWSとの通信経路を設定します。
接続する先
VIF(Virtual Interface)を使用して接続する先としてゲートウェイを指定します。具体的には、AWS側で設定するゲートウェイは、以下のいずれかのものです:
1. プライベートVIFの場合(Private Virtual Interface)
- 指定するゲートウェイ: 仮想プライベートゲートウェイ(VGW)
- 役割: 仮想プライベートゲートウェイ(VGW)は、AWS VPC内のリソースとオンプレミスネットワークを接続するためのゲートウェイです。Private VIFを設定すると、VIFはこのVGWを介してVPC内のリソースと接続されます。
- 設定方法: AWS側で仮想プライベートゲートウェイを作成し、Direct ConnectのPrivate VIFに接続します。
- オンプレミスネットワーク → VIF(AWS Direct Connect) → 仮想プライベートゲートウェイ(VGW) → VPC内のリソース(EC2、RDSなど)
フロー:
2. パブリックVIFの場合(Public Virtual Interface)
- 指定するゲートウェイ: AWSのパブリックエンドポイント
- 役割: パブリックVIFを設定すると、VIFはAWSのパブリックサービス(S3、DynamoDB、SNSなど)に接続されます。ここでは特定の「ゲートウェイ」という名前のゲートウェイを指定するのではなく、パブリックサービスのエンドポイントが利用されます。
- 設定方法: AWS側でPublic VIFを作成し、AWSのパブリックサービスにアクセスできるように設定します。
- オンプレミスネットワーク → VIF(AWS Direct Connect) → AWSパブリックサービス(S3、DynamoDBなど)
フロー:
3. トランジットVIFの場合(Transit Virtual Interface)
- 指定するゲートウェイ: Transit Gateway(TGW)
- 役割: Transit VIFは、AWSのTransit Gateway(TGW)を使って複数のVPCやオンプレミスネットワークを接続するために使用されます。Transit Gatewayを利用することで、複数のVPCや外部ネットワークを集約して効率的に通信を行うことができます。
- 設定方法: AWS側でTransit Gatewayを作成し、VIFをTransit Gatewayに接続します。
- オンプレミスネットワーク → VIF(AWS Direct Connect) → Transit Gateway(TGW) → 複数のVPCや他のネットワーク
フロー:
まとめ
- Private VIFの場合は、仮想プライベートゲートウェイ(VGW)を指定します。
- Public VIFの場合は、AWSのパブリックサービスのエンドポイントを指定します。
- Transit VIFの場合は、Transit Gateway(TGW)を指定します。
VIFの種類に応じて、接続先のゲートウェイが異なるため、目的に応じて適切な設定を行うことが重要です。
AWS Direct Connect と Site-to-Site VPN
以下は AWS Direct Connect と Site-to-Site VPN の主要な違いと共通点を整理した表です。
特徴 | AWS Direct Connect | Site-to-Site VPN |
接続方法 | 専用線(物理的な接続)を使用 | 公共インターネットを使用 |
接続の安定性 | 高い安定性と低遅延 | インターネット接続に依存するため、安定性は変動する |
仮想インターフェイス(VIF) | プライベートVIF を使用(専用線接続) | VPN VIF を使用(インターネット経由) |
帯域幅 | 高速(最大100Gbpsまで対応) | 通常はインターネット回線の帯域幅に依存 |
データ転送のセキュリティ | 高いセキュリティ(暗号化なし、専用線での通信) | 高いセキュリティ(IPsecでの暗号化) |
接続先範囲 | 単一リージョンまたは複数リージョンへの接続が可能 | 主に1つのVPCへの接続が可能 |
コスト | 高め(専用線のコストがかかる) | 比較的安価(インターネット経由のため) |
冗長性 | 冗長性を持たせるためには、複数のDirect Connect接続を設定 | VPN接続に冗長性を持たせるには、複数のVPNゲートウェイ設定が必要 |
共通点
- 両者とも、オンプレミスと AWS 間の安全な通信を提供します。
- 両方とも、仮想インターフェイス(VIF)を使用して通信を設定し、AWS に接続します。
違い
- AWS Direct Connect は専用線接続を使用し、物理的な接続による安定性と高帯域幅が特徴です。一方、Site-to-Site VPN はインターネット経由で接続するため、VPNの暗号化を使用して安全性を確保しますが、インターネットの状態によって安定性が変動する可能性があります。
![[新機能] AWS Direct Connect Gatewayで世界中のAWSリージョンとプライベート接続する | DevelopersIO](https://www.notion.so/image/https%3A%2F%2Fdev.classmethod.jp%2Ffavicon.ico?table=block&id=1a8d7ae8-88e2-8095-a758-cf121b8d2ef2&t=1a8d7ae8-88e2-8095-a758-cf121b8d2ef2)
![[新機能] AWS Direct Connect Gatewayで世界中のAWSリージョンとプライベート接続する | DevelopersIO](https://www.notion.so/image/https%3A%2F%2Fdevio2023-media.developers.io%2Fwp-content%2Fuploads%2F2016%2F02%2Fdirect-connect-eyecatch.png?table=block&id=1a8d7ae8-88e2-8095-a758-cf121b8d2ef2&t=1a8d7ae8-88e2-8095-a758-cf121b8d2ef2)


実践
Site-to-Site VPNとよく似ているから、Site-to-Site VPNで練習してみましょぅ!


一問道場
背景
- 企業は 1本のAWS Direct Connect(1 Gbps接続) を使い、1つのリージョンにあるVPCとオンプレミスを接続しています。
- 現在、1つのプライベート仮想インターフェイス(VIF)を使っています。
要件
- 冗長性を持たせるために、同じリージョン内で 新しいDirect Connect接続 を追加する。
- 今後、他のリージョンにも接続を拡張できるようにする。
- 複数リージョン対応 が可能な設計が必要。
選択肢の内容
A: Direct Connect Gatewayを使用する方法
- Direct Connect Gatewayを作成する。
- 既存のプライベートVIFを削除 し、新しいDirect Connect接続を作成。
- それぞれの接続に 新しいプライベートVIF を作成し、Direct Connect Gatewayに接続する。
- 最後にDirect Connect GatewayをVPCに接続。
B: 既存の構成を維持して追加接続を行う方法
- 既存のプライベートVIFはそのまま使用する。
- 新しいDirect Connect接続 を作成し、そこに新しいプライベートVIFを設定。
- VPCに接続する。
C: パブリックVIFを利用する方法
- 既存のプライベートVIFを維持。
- 新しいDirect Connect接続 を作成し、そこに パブリックVIF を設定。
- VPCに接続する。
D: Transit Gatewayを使用する方法
- Transit Gatewayを作成 する。
- 既存のプライベートVIFを削除 し、新しいDirect Connect接続を作成。
- 両方の接続に 新しいプライベートVIF を設定し、Transit Gatewayに接続。
- Transit GatewayをVPCに関連付ける。
解説
この問題の解説では、求められている要件と各選択肢を照らし合わせていきます。
問題の要件
- 冗長性の追加: 既存の 1 Gbps の Direct Connect 接続に加えて、冗長の接続を追加する必要があります。
- 複数のリージョンへの接続: 今後のリージョン拡張を見越して、複数のリージョンへの接続が可能なソリューションが求められています。
各選択肢の解説
A. Direct Connect ゲートウェイを使用
- 概要: Direct Connect ゲートウェイをプロビジョニングし、両方の接続(元の接続と新しい接続)をこのゲートウェイに接続する方法です。このゲートウェイは、複数の VPC やリージョンに接続するためのソリューションであり、拡張性を提供します。
- 解説:
- 冗長性: 2つの Direct Connect 接続を使って冗長性を確保できます。
- 複数リージョン対応: Direct Connect ゲートウェイを使用することで、異なるリージョンにある VPC への接続が可能です。
- この方法は要件を満たしており、最適な解決策です。
B. 新しいプライベート仮想インターフェースを作成
- 概要: 既存の接続にプライベート仮想インターフェースを維持し、新しい接続に別のプライベート仮想インターフェースを作成して単一の VPC に接続する方法です。
- 解説:
- 冗長性: 2つの接続で冗長性を提供しますが、1つのリージョン内での接続に限られます。
- 複数リージョン対応: 複数リージョンに接続するための機能はなく、このソリューションは将来のリージョン拡張には適していません。
- この選択肢は、冗長性のためには有効ですが、複数リージョンには対応できません。
C. 新しいパブリック仮想インターフェースを作成
- 概要: 既存の接続にプライベート仮想インターフェースを維持し、新しい接続にパブリック仮想インターフェースを作成して単一の VPC に接続する方法です。
- 解説:
- 冗長性: 2つの接続で冗長性を提供しますが、パブリック仮想インターフェースを使うことは、VPC への直接接続には適しません。
- 複数リージョン対応: 複数リージョンへの接続には対応していません。パブリックインターフェースは通常、インターネット接続や AWS サービスへのアクセスに使用されますが、VPC への接続には適していません。
- この方法は要件に適していません。
D. トランジットゲートウェイを使用
- 概要: トランジットゲートウェイを使用して、2つの Direct Connect 接続を接続し、その後それを VPC に関連付ける方法です。
- 解説:
- 冗長性: 2つの接続で冗長性を確保できますが、トランジットゲートウェイは通常、VPC 間接続や複数 VPC を統合するために使用されます。
- 複数リージョン対応: トランジットゲートウェイは、VPC 間接続を簡素化するためのツールですが、Direct Connect 接続の冗長性や複数リージョン対応には特に強みはありません。リージョンを越えた接続を作成する場合には、Direct Connect ゲートウェイの方が適しています。
- この方法も冗長性を提供しますが、複数リージョン対応の観点では最適ではありません。
結論
- 最適な解決策は A です。Direct Connect ゲートウェイを使用することで、冗長性を確保し、将来のリージョン拡張にも対応できるため、要件を満たす最適な方法です。
ポイント
- 他リージョン対応 を考慮する場合、Direct Connect Gatewayが適している。
- Direct Connect Gatewayは 複数のリージョン間接続 をサポートするため。
- 冗長性を高めるには、複数の接続と仮想インターフェイス(VIF)が必要。
- パブリックVIF(選択肢C)は、S3などのAWSパブリックサービスに使うもので、今回の要件には適さない。
正解
A: Direct Connect Gatewayを使用する方法
- 冗長構成 + 他リージョン接続の拡張性を満たす設計です。
018-Rekognition
実践




一問道場
ある企業には、ユーザーが短い動画をアップロードできるウェブアプリケーションがあります。
動画は Amazon EBS ボリューム に保存され、カスタム認識ソフトウェアで分析されてカテゴリ分けされています。
現状のアーキテクチャ:
- ウェブサイトには静的コンテンツがあり、特定の月にトラフィックが急増します。
- ウェブアプリケーション のために Amazon EC2 インスタンス が Auto Scaling グループ で実行されています。
- 動画の処理は Amazon SQS キュー を使用し、EC2 インスタンス がそのキューを処理します。
企業の目標:
- 運用負荷を削減し、AWS の マネージドサービス を利用し、サードパーティ製ソフトウェア への依存を排除する。
- 既存のシステムを 再アーキテクチャ して、効率的で管理しやすいものに変更したい。
要件を満たすソリューションはどれか?
選択肢:
- A. Amazon ECS コンテナをウェブアプリケーションに使用し、Auto Scaling グループで SQS キューを処理するためにスポットインスタンスを使用します。カスタムソフトウェアを Amazon Rekognition に置き換えて、動画をカテゴリ分けします。
- B. アップロードされた動画を Amazon EFS に保存し、ウェブアプリケーションの EC2 インスタンスにファイルシステムをマウントします。SQS キューを AWS Lambda 関数で処理し、Amazon Rekognition API を呼び出して動画をカテゴリ分けします。
- C. ウェブアプリケーションを Amazon S3 にホストし、アップロードされた動画も Amazon S3 に保存します。S3 イベント通知 を使用して SQS キューにイベントを公開します。SQS キューを AWS Lambda 関数で処理し、Amazon Rekognition API を呼び出して動画をカテゴリ分けします。
- D. AWS Elastic Beanstalk を使用して、ウェブアプリケーションのために Auto Scaling グループで EC2 インスタンスを起動し、SQS キューを処理するためにワーカー環境を起動します。カスタムソフトウェアを Amazon Rekognition に置き換えて、動画をカテゴリ分けします。
要点整理:
- 企業は運用負荷を減らし、AWS のマネージドサービスを活用したい。
- 動画を分類するためのカスタムソフトウェアを Amazon Rekognition に置き換えたい。
- 動画やデータのストレージや処理を Amazon S3 や AWS Lambda のようなマネージドサービスに移行することが求められている。
解説
この問題では、企業が運営している動画アップロードウェブアプリケーションを再アーキテクチャして、運用負荷を減らし、AWSのマネージドサービスを利用するという目的に適したソリューションを選ぶ必要があります。具体的には、動画の保存、処理、ウェブアプリケーションのホスティングを効率的に行いたいという要件があります。
以下、選択肢ごとの解説を行います。
A. Amazon ECSコンテナをウェブアプリケーションに使用し、Auto ScalingグループでSQSキューを処理するためにスポットインスタンスを使用します。カスタムソフトウェアをAmazon Rekognitionに置き換えて、動画をカテゴリ分けします。
- ECSコンテナを使用する点では、運用負荷を軽減し、スケーラビリティを向上させることができます。しかし、ここで問題となるのは、動画の保存方法です。問題文には動画がEBSに保存されているとありますが、この選択肢では動画保存場所が明示されていません。
- また、スポットインスタンスを使用するのは、コスト削減には効果的ですが、スポットインスタンスは時折停止される可能性があり、重要な処理に適さないことがあります。
- 結論として、動画の保存方法と安定性に関して不明点があり、最適ではないと言えます。
B. アップロードされた動画をAmazon EFSに保存し、ウェブアプリケーションのEC2インスタンスにファイルシステムをマウントします。SQSキューをAWS Lambda関数で処理し、Amazon Rekognition APIを呼び出して動画をカテゴリ分けします。
- Amazon EFS(Elastic File System) は、複数のEC2インスタンスから同時にアクセスできるファイルシステムです。この選択肢では、EC2インスタンスでウェブアプリケーションをホストし、EFS を用いて複数インスタンス間で動画を共有する方法です。EFSは可用性が高く、ファイルの共有が可能ですが、運用の効率化という点では、EFSの管理はやや手間がかかる場合もあります。
- また、Lambda を使って動画処理を行うという点は、マネージドサービスを活用した効率的な解決策ですが、動画の保存方法としてはS3の方がよりスケーラブルで低コストです。
- 結論として、EFSは利用可能ではありますが、S3の方がよりAWSのマネージドサービスに適しており、運用の手間を減らす意味でも効果的です。
C. ウェブアプリケーションをAmazon S3にホストし、アップロードされた動画もAmazon S3に保存します。S3イベント通知を使用してSQSキューにイベントを公開します。SQSキューをAWS Lambda関数で処理し、Amazon Rekognition APIを呼び出して動画をカテゴリ分けします。
- Amazon S3 は動画の保存に最適なAWSのオブジェクトストレージサービスです。高いスケーラビリティ、低コスト、容易な管理を提供します。動画をアップロードする際にS3イベント通知を利用して、動画がアップロードされると自動的にSQSキューにイベントを送信できます。
- AWS Lambda を使って動画処理を行うことで、サーバー管理の負担を減らすことができます。Amazon Rekognition を呼び出して動画を自動的にカテゴリ分けする点も効率的です。
- Amazon S3 に動画を保存し、Lambda で処理を行うことで、運用の手間を最小限に抑えることができます。
- 結論として、この選択肢はAWSのマネージドサービスを最大限活用でき、運用負荷を削減し、コスト効率が高いため、最も適切です。
D. AWS Elastic Beanstalkを使用して、ウェブアプリケーションのためにAuto ScalingグループでEC2インスタンスを起動し、SQSキューを処理するためにワーカー環境を起動します。カスタムソフトウェアをAmazon Rekognitionに置き換えて、動画をカテゴリ分けします。
- AWS Elastic Beanstalk は、アプリケーションのデプロイと管理を簡素化するマネージドサービスで、Auto Scalingやロードバランシングも自動で処理します。Elastic Beanstalkは便利ですが、既に他の選択肢で説明されているLambdaやS3と組み合わせたソリューションの方が運用の効率化には有利です。
- また、Elastic Beanstalk でEC2インスタンスを管理するのは、一定の運用負荷が残ります。Lambda や S3 を活用する方がよりシンプルで効果的です。
- 結論として、この選択肢は一部でマネージドサービスを利用していますが、運用効率を最大化するためには他の選択肢がより適切です。
最適解:C
Cの選択肢が最も適切です。理由としては、Amazon S3 と AWS Lambda の組み合わせが、動画の保存、処理、カテゴリ分けにおいて運用負荷を最小限に抑え、スケーラビリティとコスト効率に優れているためです。
019-動画アプローチ to S3
理論
AWS Transfer Family は、ファイル転送プロトコル (FTP, SFTP, FTPS) を使用してデータを AWS に転送するためのマネージドサービスです。このサービスは、安全でスケーラブルな方法でデータをクラウドに取り込み、ストレージや分析ワークフローで利用できるようにします。
特徴
- プロトコル対応:
- SFTP (Secure File Transfer Protocol): 暗号化された安全なファイル転送を提供。
- FTP (File Transfer Protocol): 基本的なファイル転送。
- FTPS (File Transfer Protocol over SSL): セキュリティのために SSL/TLS を使用。
- バックエンドストレージ:
- Amazon S3 や Amazon EFS と連携して、ファイルを保存および管理します。
- セキュリティ:
- IAM ロールを使用した認証や、既存の ID プロバイダー (AD, LDAP, IAM Identity Center など) と統合可能。
- データ転送中および保存中の暗号化をサポート。
- スケーラビリティ:
- マネージドサービスのため、インフラ管理が不要で、負荷に応じて自動でスケーリングします。
- 簡単な移行:
- 既存のオンプレミスまたはレガシーなファイル転送ワークフローを最小限の変更でクラウドに移行可能。
ユースケース
- データ取り込み:
- パートナーや顧客から定期的に送られるデータを AWS に安全に取り込み、S3 や分析ツールで処理。
- レガシーシステムのクラウド移行:
- オンプレミスのファイル転送システムをクラウドベースに置き換える。
- 安全なファイル共有:
- 外部ユーザーや部門間でのセキュアなデータ共有を実現。
- ビッグデータと分析:
- 定期的に送信される大規模なデータセットを AWS で保存し、Athena や Redshift などで分析。
仕組み
- エンドポイントの作成:
- AWS Transfer Family コンソールで、使用するプロトコル (例: SFTP) のエンドポイントを作成。
- ユーザー管理:
- IAM または既存の ID 管理システムで、ユーザーごとのアクセス制御を設定。
- データ転送:
- クライアントソフトウェア (例: WinSCP, FileZilla) を使ってエンドポイントに接続し、ファイルを転送。
- バックエンド処理:
- ファイルは S3 または EFS に保存され、その後、他の AWS サービスと連携して処理。
利点
- コスト効率: インフラの管理やメンテナンス不要。
- 互換性: 既存のファイル転送クライアントやスクリプトをそのまま利用可能。
- セキュリティ: AWS のセキュリティサービスとの統合。
AWS Transfer Family は、従来のファイル転送をクラウドに統合したい場合に非常に有用です。
AWS Transfer Family が IAM Identity Center (AWS SSO) と統合される場合、IAM Identity Center のインスタンスの「組織インスタンス」または「アカウントインスタンス」を作成する選択肢には、それぞれ異なるユースケースと運用上の意味があります。以下に違いを説明します:
1. 組織インスタンス (Organization Instance)
- 概要: AWS Organizations を使用している場合、このインスタンスを選択します。
- 特徴:
- マルチアカウント対応: 複数の AWS アカウント間で IAM Identity Center を共有し、一元的にユーザーやグループ、アクセスを管理できます。
- 中央管理: 管理者は、Organizations に参加している複数の AWS アカウントに対して一括でユーザーやグループの権限を割り当てられる。
- 最適なユースケース: 企業規模での利用を想定しており、複数の AWS アカウントやリソースを運用する組織に向いている。
2. アカウントインスタンス (Account Instance)
- 概要: 個別の AWS アカウント内で IAM Identity Center を使用する場合に選択します。
- 特徴:
- シングルアカウント対応: 単一の AWS アカウント内でのみユーザーやグループを管理します。
- 限定的なスコープ: 他のアカウントにまたがったアクセス管理や権限設定はできません。
- 最適なユースケース: 小規模なプロジェクトや、単一アカウントで完結するシンプルな構成。
選択のポイント
- AWS Organizations を使っているかどうか:
- 使っている → 組織インスタンス。
- 使っていない → アカウントインスタンス。
- 管理する範囲:
- マルチアカウントや中央管理が必要 → 組織インスタンス。
- 単一アカウント内で十分 → アカウントインスタンス。
- 複雑さ:
- 組織インスタンスは設定や運用が複雑になることがあるが、スケーラビリティが高い。
- アカウントインスタンスは簡単に構築・管理できるが、柔軟性は低い。
例:
- 企業全体のファイル転送システムを構築し、複数アカウントにまたがるユーザーとグループを管理したい場合 → 組織インスタンス。
- 小規模なチームやプロジェクト単位で AWS Transfer Family を使いたい場合 → アカウントインスタンス。
必要な要件に基づいて適切なインスタンスを選択することをお勧めします!
Access Grants
Access Grants は Amazon S3 のアクセス管理を簡単にする機能です。IAM Identity Center と統合し、以下が実現できます。
特徴
- シンプルなアクセス管理:
ノーコードでユーザーやグループにアクセス権を割り当て可能。
- IAM Identity Center 連携:
シングルサインオン (SSO) で認証し、アクセスを管理。
- 自動ポリシー生成:
S3 バケットやオブジェクトへの権限を自動的に設定。
メリット
- 運用が簡単: ポリシーの手動設定が不要。
- セキュリティ強化: ユーザー認証とアクセス管理を一元化。
- 効率的な管理: ユーザー・グループ単位で柔軟にアクセス設定。
まとめ:
Access Grants は S3 のアクセス管理を効率化 し、IAM Identity Center と連携して安全かつ簡単にユーザーアクセスを制御できる機能です。
実践
![[AWS Transfer Family web apps] S3にアクセスできるWebアプリケーションをさくっと作ってみた | DevelopersIO](https://www.notion.so/image/https%3A%2F%2Fdev.classmethod.jp%2Ffavicon.ico?table=block&id=1a8d7ae8-88e2-80ac-9311-dcf02a925899&t=1a8d7ae8-88e2-80ac-9311-dcf02a925899)
![[AWS Transfer Family web apps] S3にアクセスできるWebアプリケーションをさくっと作ってみた | DevelopersIO](https://www.notion.so/image/https%3A%2F%2Fimages.ctfassets.net%2Fct0aopd36mqt%2Fwp-thumbnail-dd57f8260eaf825c214225faa0278acc%2Fc6d3e347c61a60abea783c1132a311be%2Faws-transfer-family?table=block&id=1a8d7ae8-88e2-80ac-9311-dcf02a925899&t=1a8d7ae8-88e2-80ac-9311-dcf02a925899)




今回実施する構成図

1.AWS Transfer Family で S3 バケットへのファイル転送設定を作成する。
はじめに
S3のファイルを操作できるWebアプリケーションがコード不要で作成できるとあったので、構築してみました。
準備
- IAM Identity Center が有効になっていること
- WebアプリケーションからアクセスしたいS3バケットが作成済みであること
構築手順(ざっくり)
- AWS Transfer Familyからウェブアプリを作成
- ウェブアプリにIdentity Centerのユーザー or グループを割り当てる
- S3 Access Grantsを作成
- S3 バケットを選択
- アクセスしたいパス/プレフィクスを設定
- Permissionsを設定(Read/Write)
- プリンシパルタイプ(ユーザー or グループ)を設定
- S3にCORSポリシーを設定
- 完了
手順としては4ステップでWebアプリケーションが作成できます。
最後におまけとしてユーザー毎にアクセスを制限する方法を紹介します。
それでは解説していきます
AWS Transfer Familyからウェブアプリを作成
AWS Transfer Familyのウェブアプリを選択します(最近発表されたため、新規と出ています)
必要な同時接続数を設定して次へを選択(2024年12月時点で1000が上限でした)
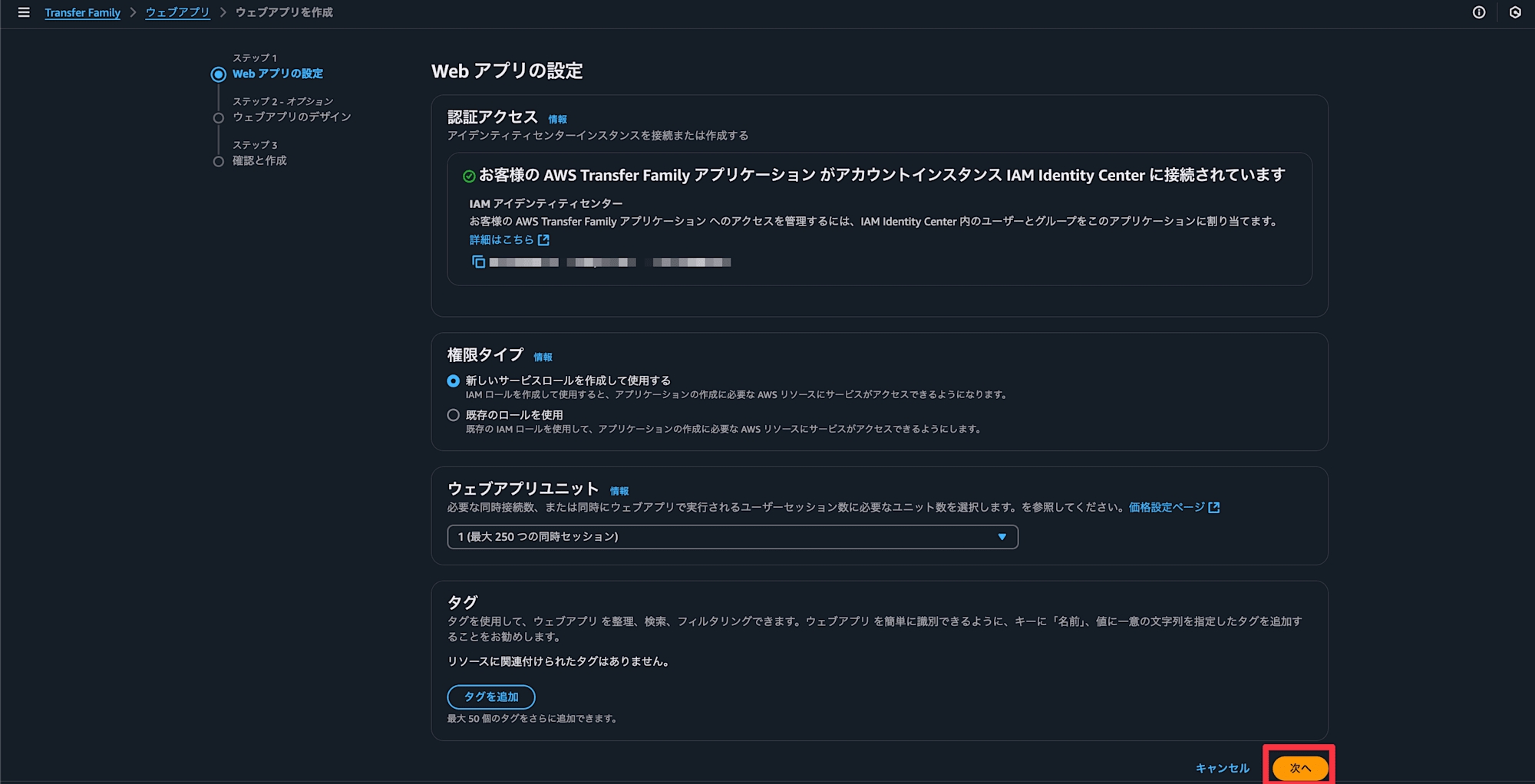
titleやロゴを設定していきます
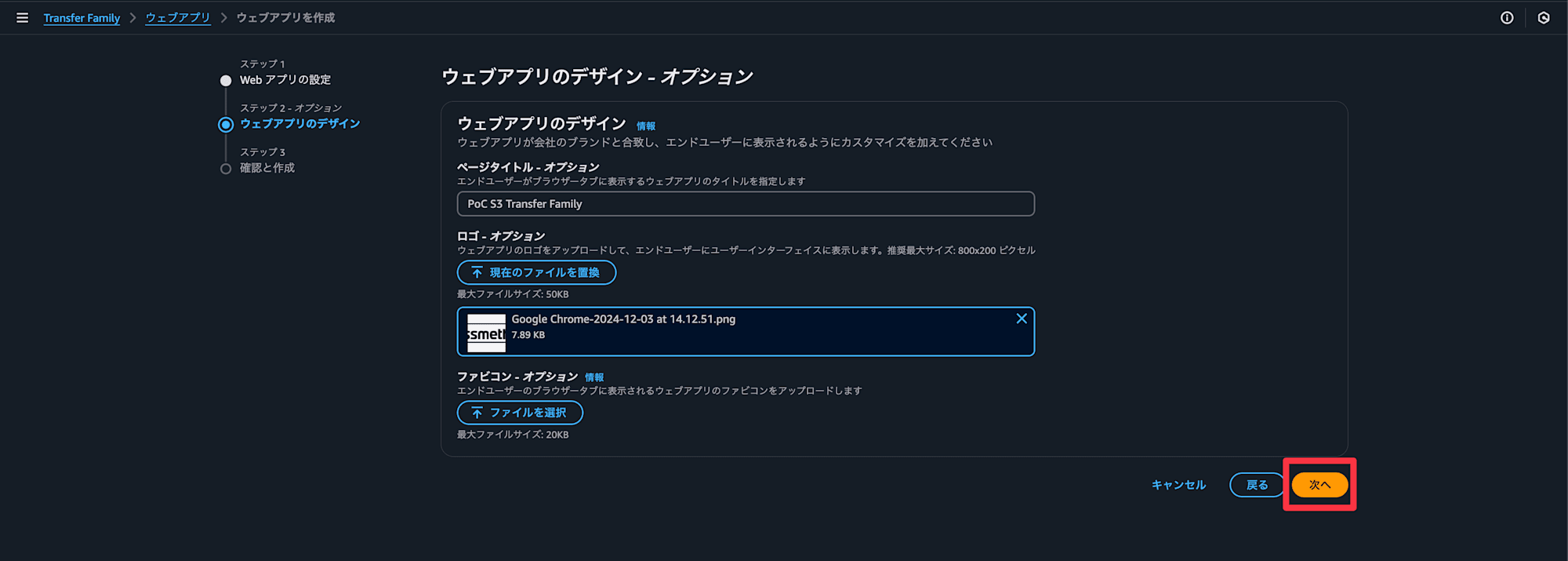
ウェブアプリを作成を選択
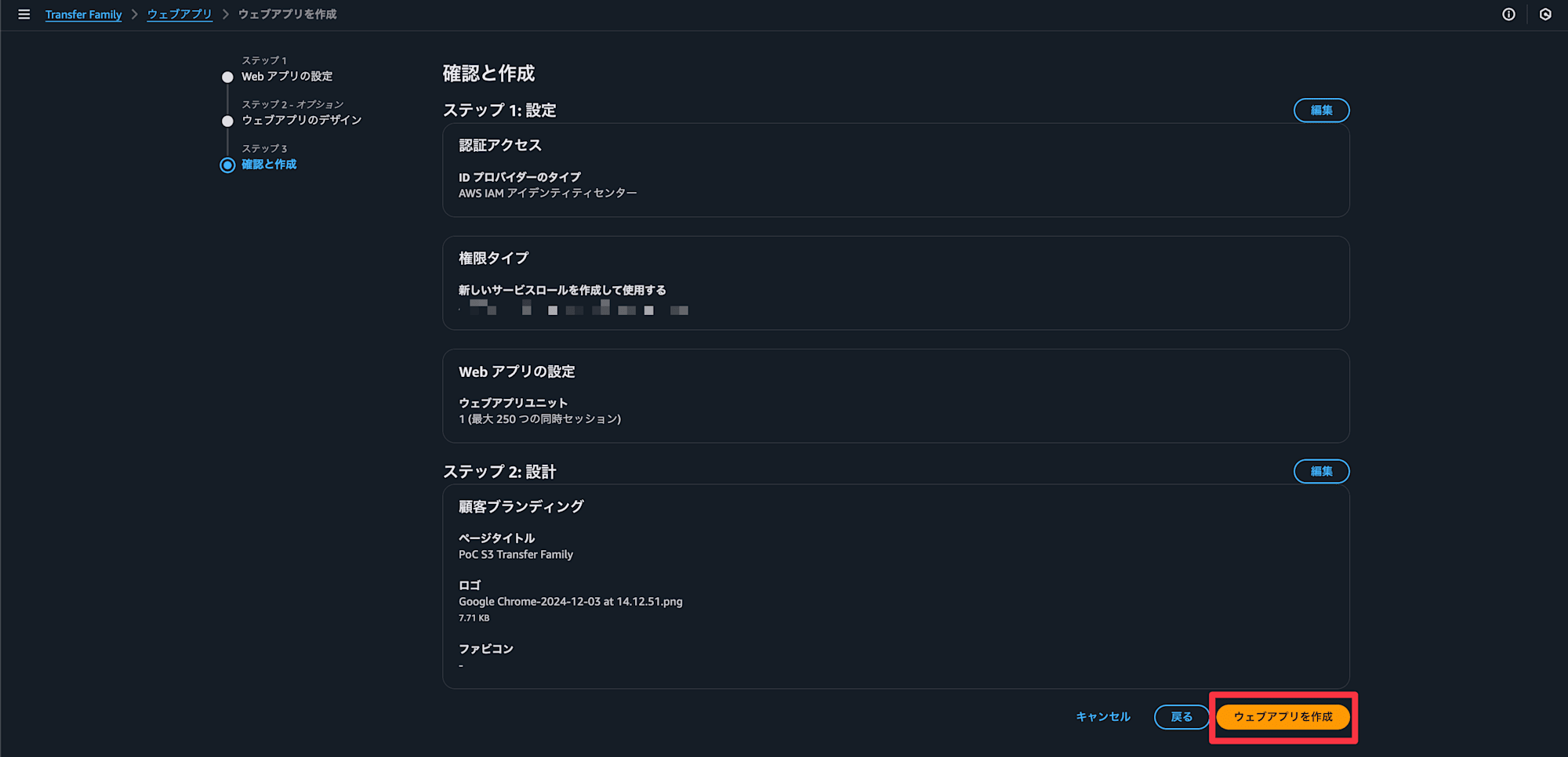
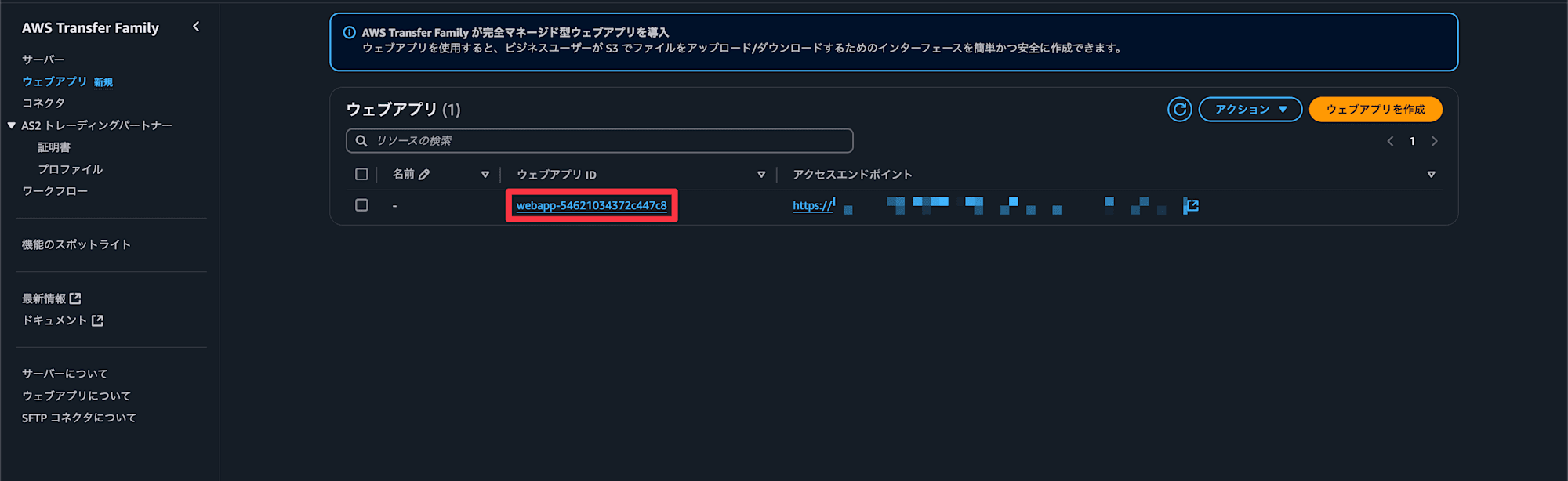
アプリケーションが作成できました。次にIdentity Centerの情報を設定していきます
ウェブアプリにIdentity Centerのユーザー or グループを割り当てる
ウェブアプリIDを選択
を選択
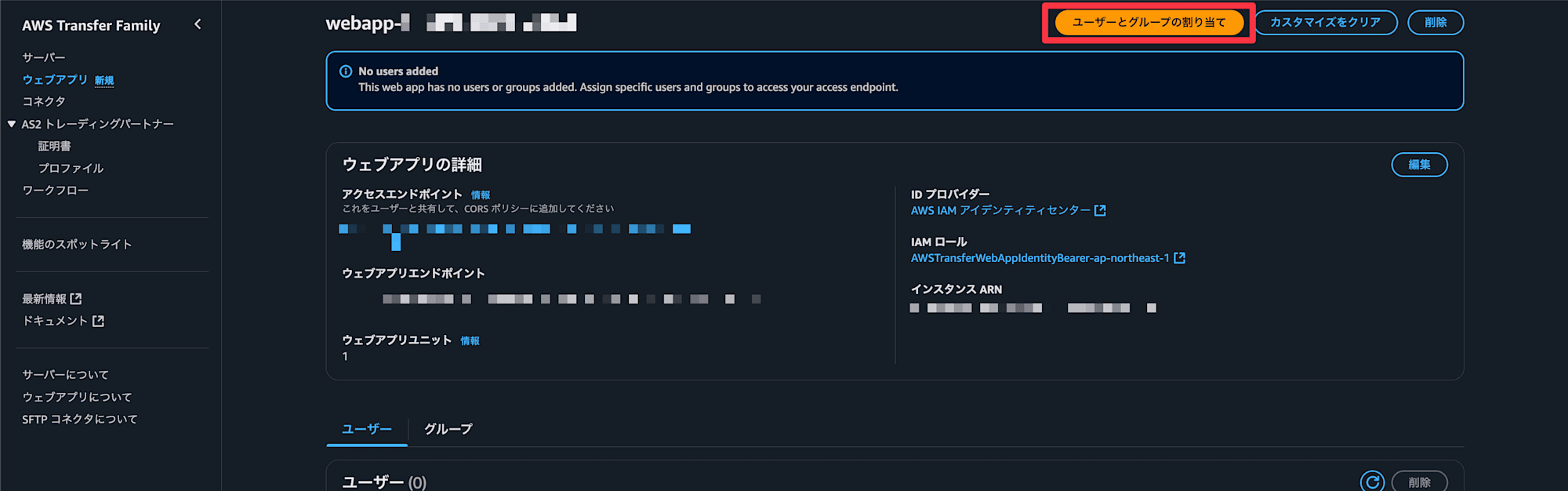
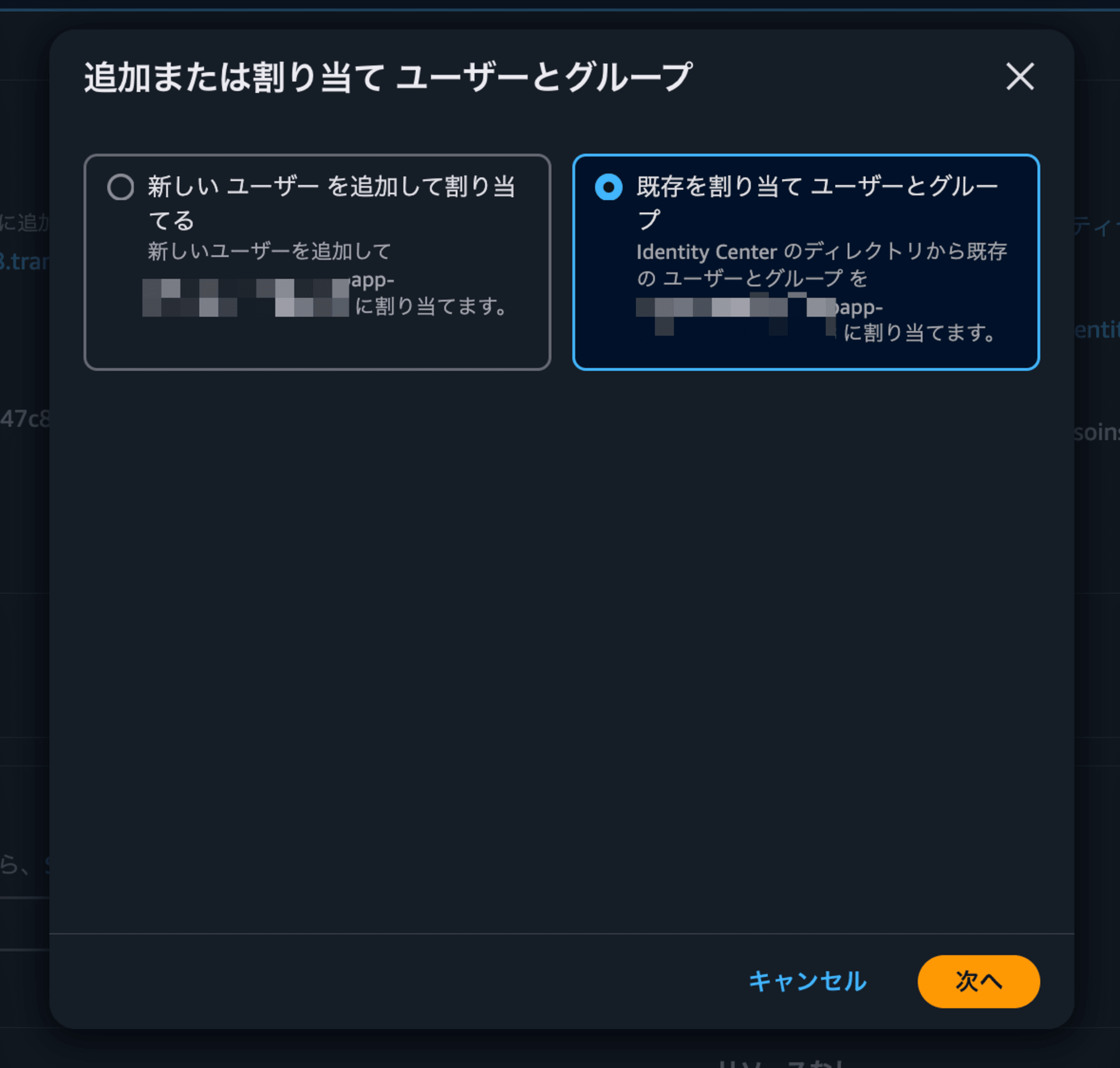
今回は
を選択します(既にIdentity Centerにユーザーやグループが作成されている状態)
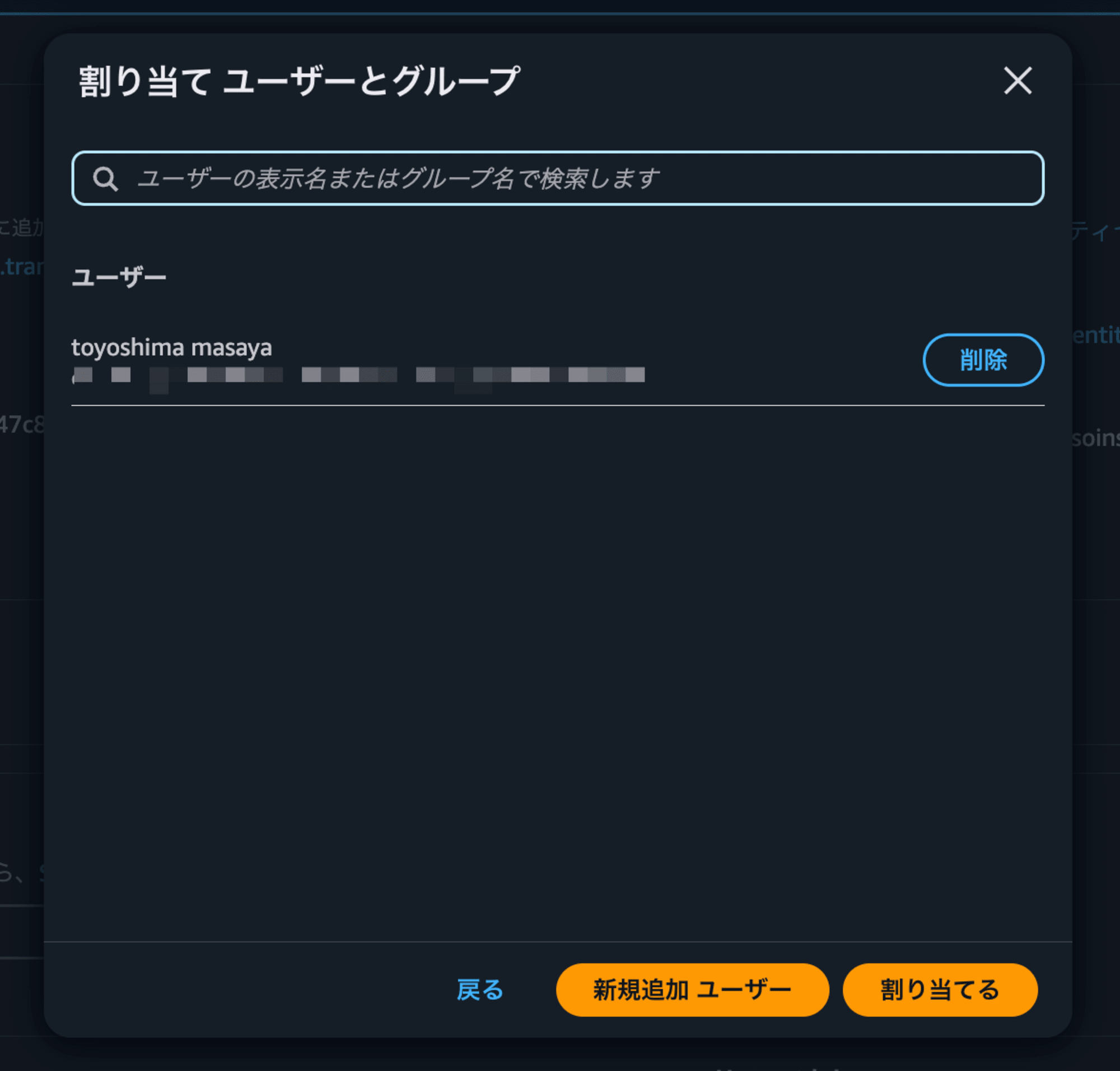
設定したいユーザーを選択→
を選択
S3 Access Grantsを作成
次にS3のAccess Grantsを作成していきます
S3のサービスページからAccess Grants→
権限を作成を選択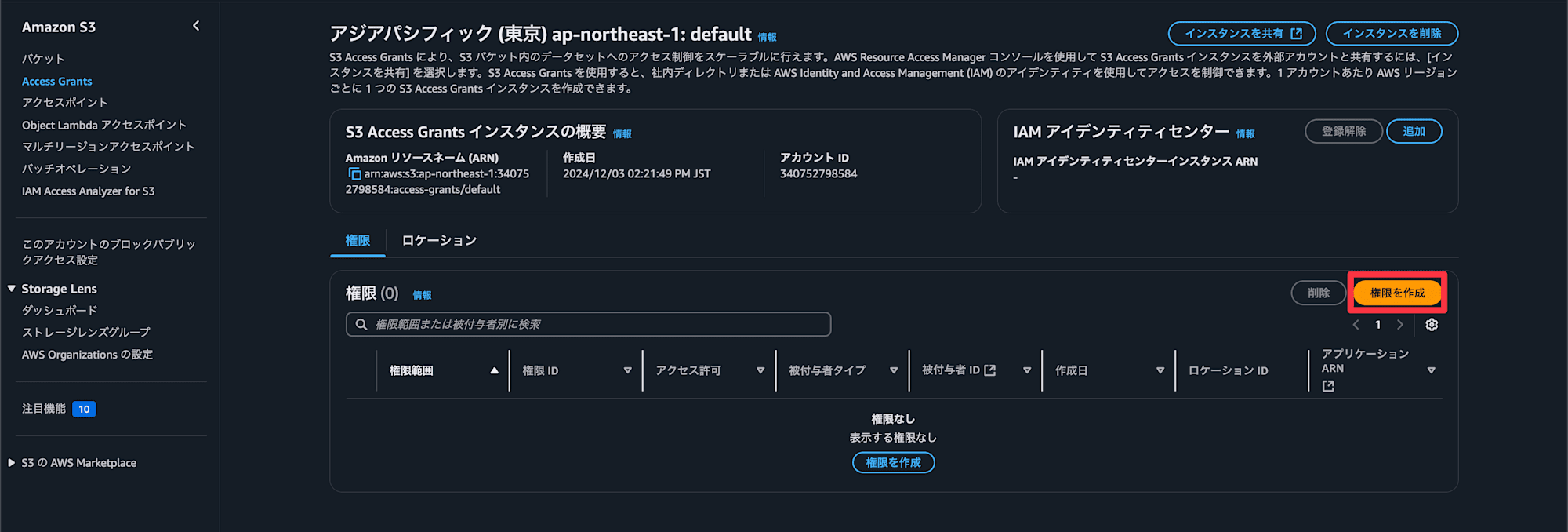
Identity Centerが設定されていない場合は追加し、
を選択
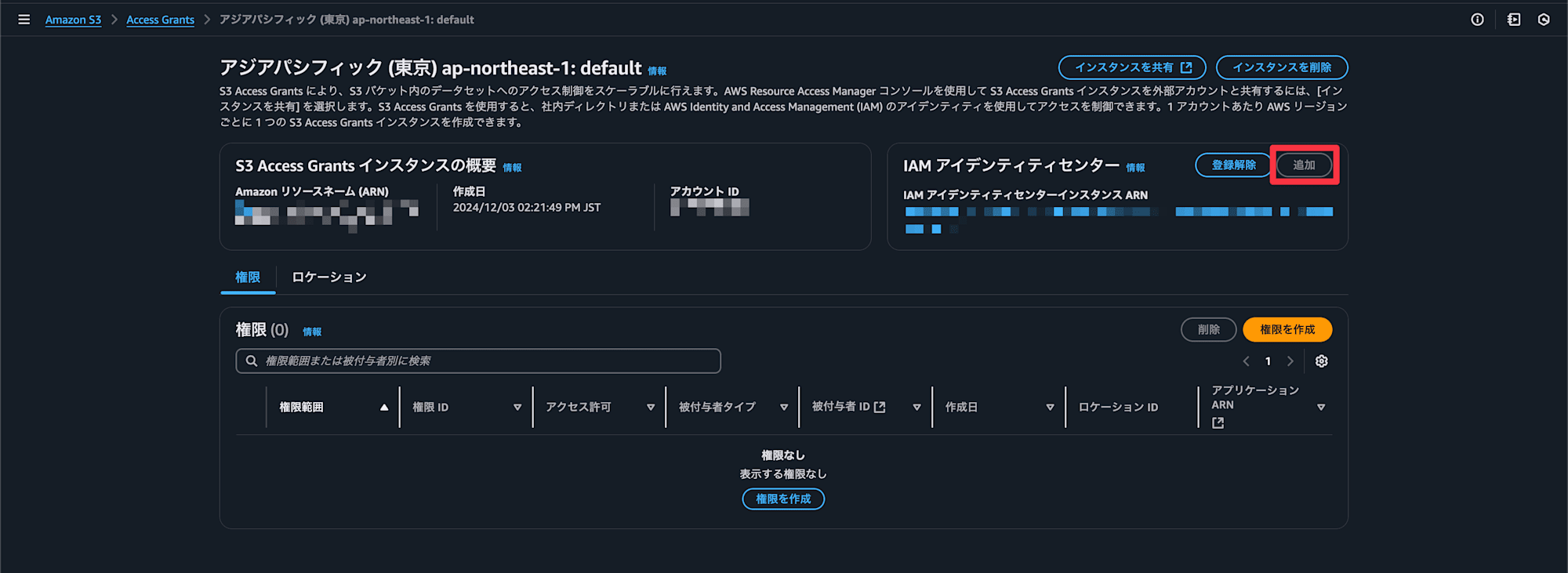
権限作成でのポイントは
- サブプレフィックス
- 許可の範囲を設定します。バケット全体でOKであれば
- 許可
- Read/Writeの設定
- 被付与者タイプ
- 今回はIdentity Centerの情報から設定します
- ディレクトリアイデンティティタイプ
- Identity Centerのユーザーもしくはグループの単位で許可を設定できます
- ここではユーザーを設定しました
CORSの設定
最後にアプリケーションからS3にアクセスするためCORSを設定します
CORS設定内容
AWS Transfer Family > ウェブアプリから確認できるウェブアプリエンドポイントを設定します
テスト用として大雑把に設定しています
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE",
"HEAD"
],
"AllowedOrigins": [
"https://{ウェブアプリエンドポイント}",
"https://*.{ウェブアプリエンドポイント}"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]ウェブアプリのアクセスエンドポイントに接続→サインインするとアクセスが許可されたパスが表示されています
パスを選択して適当な画像をアップロードします

アップロードできました
今回の権限ではダウンロードはもちろん、フォルダの作成、コピー、削除も可能です
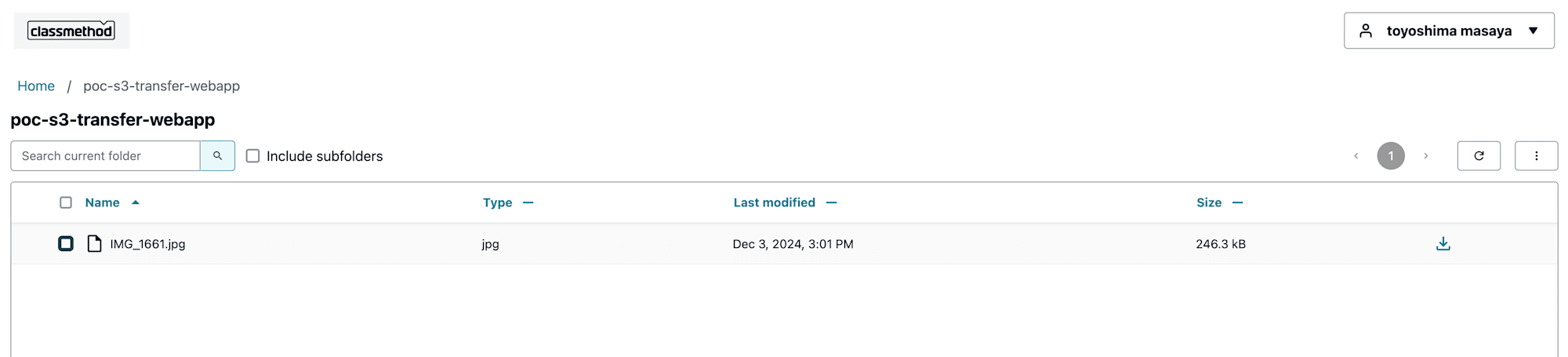
おまけ(アクセスできるパスをユーザー毎に制限してみる)
ファイルのアクセスが確認できたため、ユーザー毎にアクセスできるパスを制限してみます
例えば、部署Aの人は部署Bのパスにアクセスできない...といったシーンに活用できます
一例としてIdentity Centerのグループを利用し、グループを部署として扱います
事前準備、確認
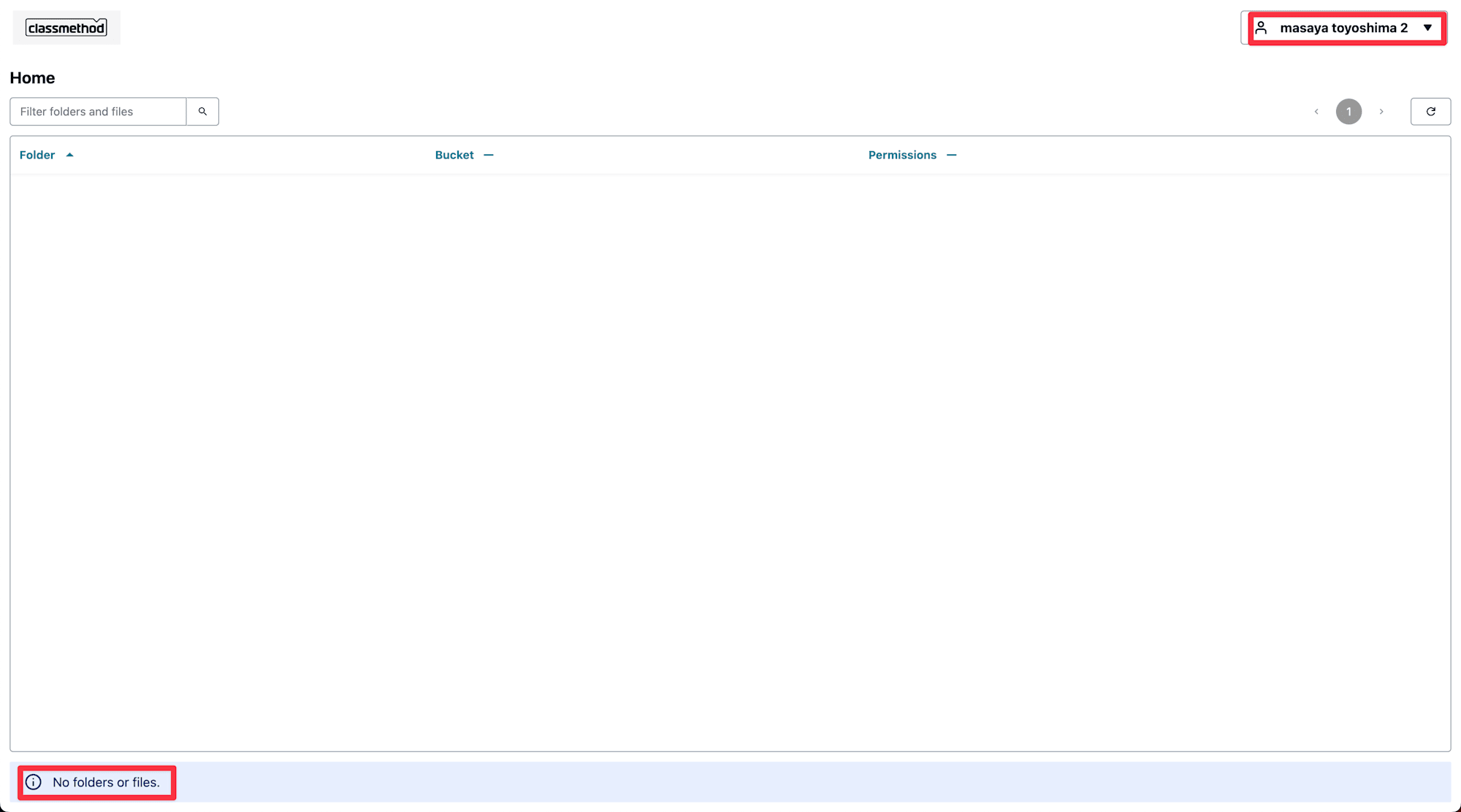
Identity Centerで新しいユーザーを作成し、
新しいユーザー(masaya toyoshima 2)を作成、サインインしましたがAccess Grantsが作成されていないため、何も表示されません
Identity Centerからグループを作成していきます
- group-a(元のユーザー
toyoshima masayaを設定)
- group-b(新しいユーザー
masaya toyoshima 2を設定)を作成、及び設定します(group-bのユーザーについては構築手順1, 2を参照)同様の手順でgroup bも作成しておきます
Access Grantsの作成からサブプレフィックスを指定します
今回は
group-a用としたいのでgroup-a/*を設定許可を設定したい権限をチェックして
被付与者タイプを
アイデンティティセンターからのディレクトリIDディレクトリアイデンティティタイプを
グループにします同様の設定でgroup-aを
group-bに置換して作成します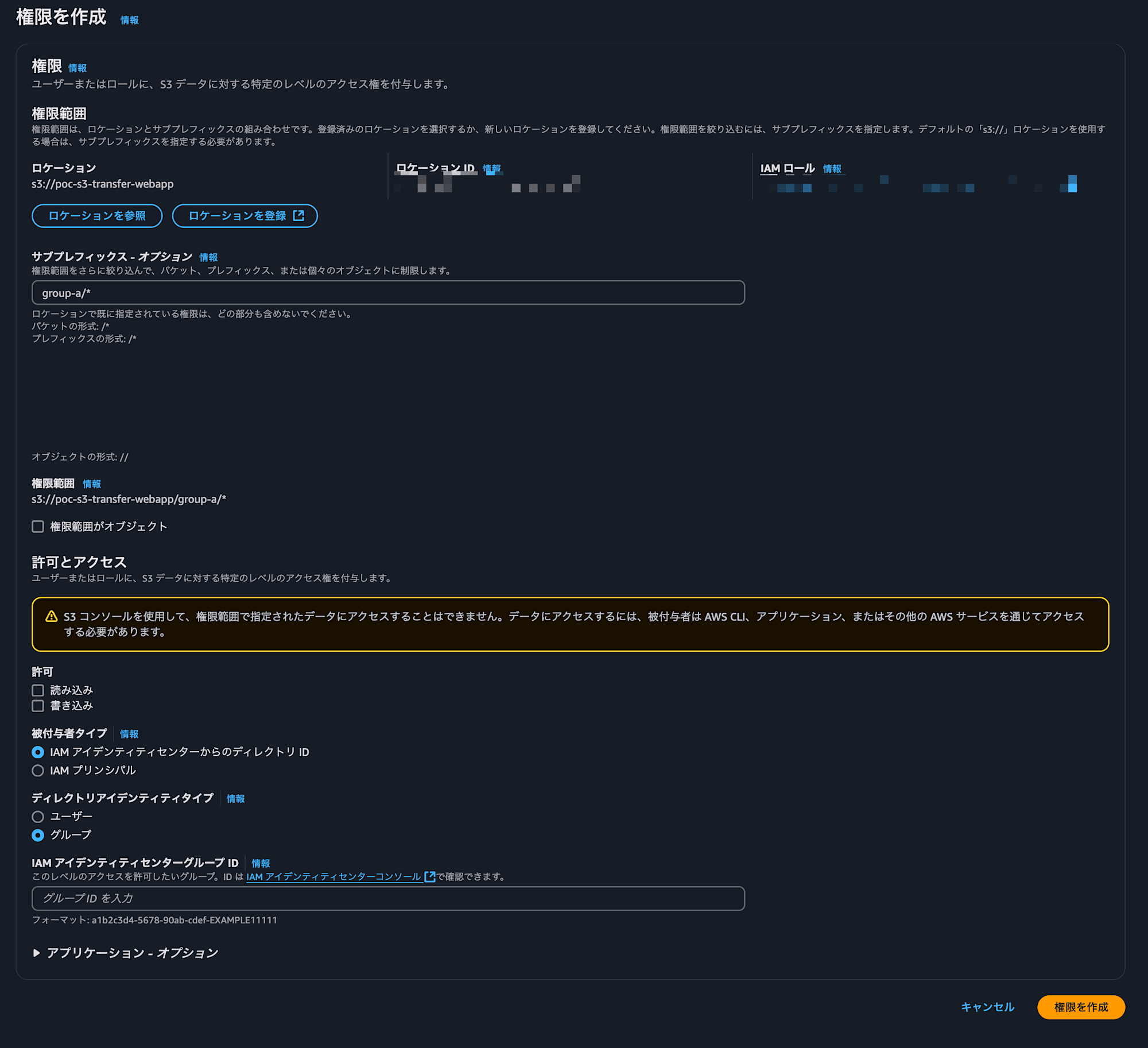
group-aのユーザーでログイン後、該当のディレクトリが表示されています(group-bはアクセス権限がないため表示されていない)

group-bのユーザーではgroup-bが表示されています(group-aはアクセス権限がないため表示されていない)

S3にファイルを格納した際にSQSキューに通知し、Lambdaでそのメッセージを処理する
S3 へのファイル格納時に SQS キューに通知をしてみるS3 SQS
はじめに
AWS認定試験に必ず出題される SQS ですが、今まで触ったことがなかったので本日は S3 と連携させて SQS を試してみたいと思います。
使用するサービス
- Amazon SQS・・・フルマネージド型のメッセージキューイングサービス
アーキテクチャ

手順
- S3 でバケットを作成
- SQS キューを作成
- S3 でイベント通知を作成
- 動作確認
1. S3 でバケットを作成
「20220807-sqs-test」というバケットを作成します。設定はデフォルトでOKです。

2. SQS キューを作成
「TestQueue」という SQS キューを作成します。

アクセスポリシーを以下のように設定します。
3. S3 でイベント通知を作成
イベント名とイベントタイプを設定し、作成した SQS キューを設定して「変更の保存」をクリックします。

4. 動作確認
バケットにファイルをアップロードします。

「メッセージを送受信」をクリックします。

「メッセージをポーリング」をクリックします。

メッセージが2件表示されます。

上のキューのメッセージ
アップロードしたファイルの情報などが記載されています。
下のキューのメッセージ
こちらは S3 からの通知など概要レベルの情報が記載されています。
さいごに
はじめて SQS を使用してみましたが設定は簡単にできました。何となく理解していたものが実際にサービスを使用することで理解が深まった気がします。次は SQS と Lambda の連携を試してみようと思います。
SQS キューのメッセージを Lambda で処理してみるLambda S3 SQS
はじめに
前回のエントリーで S3 と SQS の連携を試してみました。本エントリーはその続きで SQS キューに S3 から通知がきた後に SQS キューのメッセージを Lambda で処理してみようと思います。
使用するサービス
- Amazon SQS・・・フルマネージド型のメッセージキューイングサービス
- AWS Lambda・・・サーバーをプロビジョニングしたり管理しなくてもコードを実行できるコンピューティングサービス
アーキテクチャ

役割
- Amazon S3・・・アップロードするファイルを格納
- Amazon SQS・・・ S3 にアップロードされたファイルの情報を Lambda に送信
- AWS Lambda・・・SQS から送信されたファイル情報をもとにファイルの名前を変えて S3 に同じファイルをアップロード
手順
- IAMロールを作成
- S3 バケットを作成
- SQS キュー を作成
- Lambda 関数を作成
- 動作確認
1. IAMロールを作成
「Lambda-SQS-Execution-Role」という名前のLambda に SQS と S3 に対する実行権限を付与するロールを作成します。

2. S3 バケットを作成
前回のエントリーを参照してください。
3. SQS キュー を作成
前回のエントリーを参照してください。
4. Lambda 関数を作成
SQS キューのメッセージを処理するLambda関数を作成します。
[関数名]:sqs-message-receive
[ランタイム]:Python 3.9
[実行ロール]:Lambda-SQS-Execution-Role

SQS キューをトリガーとして追加します。


ソースコード
5. 動作確認
hane.jpg をアップロードします。

Lambdaによってhane2.jpg がバケットに作成されました。

さいごに
今回は簡単な処理だけだったので SQS を使う必要はないと思いますが、SQS と Lambda を実際にどのように連携するかを理解するためのいい勉強になりました。今度はデッドレターキューなど SQS をフルに活用できる構成を試してみたいですね。
lambdaをAmazonRekognitionに提携する
下記のコードをもっとのLambda関数に書き換えてください
そして、Lambda関数にAmazonRekognitionReadOnlyAccessの権限を追加して、テストしましょう

一問道場
ある企業には、ユーザーが短い動画をアップロードできるウェブアプリケーションがあります。
動画は Amazon EBS ボリューム に保存され、カスタム認識ソフトウェアで分析されてカテゴリ分けされています。
現状のアーキテクチャ:
- ウェブサイトには静的コンテンツがあり、特定の月にトラフィックが急増します。
- ウェブアプリケーション のために Amazon EC2 インスタンス が Auto Scaling グループ で実行されています。
- 動画の処理は Amazon SQS キュー を使用し、EC2 インスタンス がそのキューを処理します。
企業の目標:
- 運用負荷を削減し、AWS の マネージドサービス を利用し、サードパーティ製ソフトウェア への依存を排除する。
- 既存のシステムを 再アーキテクチャ して、効率的で管理しやすいものに変更したい。
要件を満たすソリューションはどれか?
選択肢:
- A. Amazon ECS コンテナをウェブアプリケーションに使用し、Auto Scaling グループで SQS キューを処理するためにスポットインスタンスを使用します。カスタムソフトウェアを Amazon Rekognition に置き換えて、動画をカテゴリ分けします。
- B. アップロードされた動画を Amazon EFS に保存し、ウェブアプリケーションの EC2 インスタンスにファイルシステムをマウントします。SQS キューを AWS Lambda 関数で処理し、Amazon Rekognition API を呼び出して動画をカテゴリ分けします。
- C. 静的のウェブアプリケーションを Amazon S3 にホストし、アップロードされた動画も Amazon S3 に保存します。S3 イベント通知 を使用して SQS キューにイベントを公開します。SQS キューを AWS Lambda 関数で処理し、Amazon Rekognition API を呼び出して動画をカテゴリ分けします。
- D. AWS Elastic Beanstalk を使用して、ウェブアプリケーションのために Auto Scaling グループで EC2 インスタンスを起動し、SQS キューを処理するためにワーカー環境を起動します。カスタムソフトウェアを Amazon Rekognition に置き換えて、動画をカテゴリ分けします。
要点整理:
- 企業は運用負荷を減らし、AWS のマネージドサービスを活用したい。
- 動画を分類するためのカスタムソフトウェアを Amazon Rekognition に置き換えたい。
- 動画やデータのストレージや処理を Amazon S3 や AWS Lambda のようなマネージドサービスに移行することが求められている。
解説
この問題では、企業が運営している動画アップロードウェブアプリケーションを再アーキテクチャして、運用負荷を減らし、AWSのマネージドサービスを利用するという目的に適したソリューションを選ぶ必要があります。具体的には、動画の保存、処理、ウェブアプリケーションのホスティングを効率的に行いたいという要件があります。
以下、選択肢ごとの解説を行います。
A. Amazon ECSコンテナをウェブアプリケーションに使用し、Auto ScalingグループでSQSキューを処理するためにスポットインスタンスを使用します。カスタムソフトウェアをAmazon Rekognitionに置き換えて、動画をカテゴリ分けします。
- ECSコンテナを使用する点では、運用負荷を軽減し、スケーラビリティを向上させることができます。しかし、ここで問題となるのは、動画の保存方法です。問題文には動画がEBSに保存されているとありますが、この選択肢では動画保存場所が明示されていません。
- また、スポットインスタンスを使用するのは、コスト削減には効果的ですが、スポットインスタンスは時折停止される可能性があり、重要な処理に適さないことがあります。
- 結論として、動画の保存方法と安定性に関して不明点があり、最適ではないと言えます。
B. アップロードされた動画をAmazon EFSに保存し、ウェブアプリケーションのEC2インスタンスにファイルシステムをマウントします。SQSキューをAWS Lambda関数で処理し、Amazon Rekognition APIを呼び出して動画をカテゴリ分けします。
- Amazon EFS(Elastic File System) は、複数のEC2インスタンスから同時にアクセスできるファイルシステムです。この選択肢では、EC2インスタンスでウェブアプリケーションをホストし、EFS を用いて複数インスタンス間で動画を共有する方法です。EFSは可用性が高く、ファイルの共有が可能ですが、運用の効率化という点では、EFSの管理はやや手間がかかる場合もあります。
- また、Lambda を使って動画処理を行うという点は、マネージドサービスを活用した効率的な解決策ですが、動画の保存方法としてはS3の方がよりスケーラブルで低コストです。
- 結論として、EFSは利用可能ではありますが、S3の方がよりAWSのマネージドサービスに適しており、運用の手間を減らす意味でも効果的です。
C. ウェブアプリケーションをAmazon S3にホストし、アップロードされた動画もAmazon S3に保存します。S3イベント通知を使用してSQSキューにイベントを公開します。SQSキューをAWS Lambda関数で処理し、Amazon Rekognition APIを呼び出して動画をカテゴリ分けします。
- Amazon S3 は動画の保存に最適なAWSのオブジェクトストレージサービスです。高いスケーラビリティ、低コスト、容易な管理を提供します。動画をアップロードする際にS3イベント通知を利用して、動画がアップロードされると自動的にSQSキューにイベントを送信できます。
- AWS Lambda を使って動画処理を行うことで、サーバー管理の負担を減らすことができます。Amazon Rekognition を呼び出して動画を自動的にカテゴリ分けする点も効率的です。
- Amazon S3 に動画を保存し、Lambda で処理を行うことで、運用の手間を最小限に抑えることができます。
- 結論として、この選択肢はAWSのマネージドサービスを最大限活用でき、運用負荷を削減し、コスト効率が高いため、最も適切です。
D. AWS Elastic Beanstalkを使用して、ウェブアプリケーションのためにAuto ScalingグループでEC2インスタンスを起動し、SQSキューを処理するためにワーカー環境を起動します。カスタムソフトウェアをAmazon Rekognitionに置き換えて、動画をカテゴリ分けします。
- AWS Elastic Beanstalk は、アプリケーションのデプロイと管理を簡素化するマネージドサービスで、Auto Scalingやロードバランシングも自動で処理します。Elastic Beanstalkは便利ですが、既に他の選択肢で説明されているLambdaやS3と組み合わせたソリューションの方が運用の効率化には有利です。
- また、Elastic Beanstalk でEC2インスタンスを管理するのは、一定の運用負荷が残ります。Lambda や S3 を活用する方がよりシンプルで効果的です。
- 結論として、この選択肢は一部でマネージドサービスを利用していますが、運用効率を最大化するためには他の選択肢がより適切です。
最適解:C
Cの選択肢が最も適切です。理由としては、Amazon S3 と AWS Lambda の組み合わせが、動画の保存、処理、カテゴリ分けにおいて運用負荷を最小限に抑え、スケーラビリティとコスト効率に優れているためです。
020-Private S3 access over VPN
理論
1. VPN(Virtual Private Network)とその利用目的
- VPNとは: VPNは、インターネット越しに安全な接続を提供するための技術です。通常、インターネットは公開されているネットワークであり、そこに送受信されるデータは暗号化されていないため、盗聴や改ざんのリスクがあります。VPNは、その通信を暗号化し、セキュリティを保ちつつ、プライベートネットワークへのアクセスを可能にします。
- VPNの利用目的: 主に、リモートワークや外部のネットワークから企業の内部ネットワークに安全に接続するために使用されます。企業の内部リソース(ファイルサーバー、データベース、アプリケーションなど)に対して、インターネット経由で安全にアクセスするための手段として広く使われています。
2. データの保存とアーカイブ
- データアーカイブ: 長期保存が求められるデータ(例えば、バックアップデータやアーカイブ文書など)は、アクセス頻度が低いため、コスト効率を重視したストレージクラスを利用することが一般的です。例えば、Amazon S3 GlacierやDeep Archiveは、データの保管には非常に安価ですが、アクセスの遅延が大きく、頻繁にアクセスされないデータに適しています。
3. セキュアなアクセス方法
- インターフェースエンドポイント: AWSでは、VPC内からS3バケットや他のAWSサービスにアクセスする際にインターフェースエンドポイントを設定することができます。これにより、インターネット越しにデータが流れることなく、AWS内のプライベートネットワーク経由でアクセスできます。これにより、セキュリティが向上し、外部からの攻撃リスクを低減できます。
- スプリットトンネルとは、VPNを使うときに、一部の通信(例えば、会社のシステムへのアクセス)はVPNを通して、その他の通信(インターネットのウェブサイトへのアクセスなど)はVPNを通さず直接インターネットに繋がるようにする設定です。これにより、VPNの負担を軽減できますが、安全性には注意が必要です。
これらの前提知識は、この問題のように企業が内部データを安全に保管し、限られたユーザーにのみアクセスを許可するための最適な技術選定に重要です。問題の本質は、低コストでセキュアなデータ保存とアクセス制御を実現する方法を選択することにあります。
実践
参照元:








上記の記事を参照して下記の構成を完成してください

- S3バケット作成
s3-for-vpn-clientという名前のS3バケットを作成します。

- Interface Endpoint と Gateway Endpoint の作成
- 必要なインターフェイスエンドポイント(Interface Endpoint)とゲートウェイエンドポイント(Gateway Endpoint)を作成します。
- 理由は下記の記事を参照して



- 証明書発行環境のセットアップ
- 下記の記事を参考にして、AWS CloudShellで証明書発行環境を高速セットアップします。


- 相互認証を有効にする
- AWS Client VPNの相互認証を有効にする手順を確認します。

- DNSサーバの設定
- クライアントVPNエンドポイントにDNSサーバを設定し、名前解決ができるようにします。特に、最後のオクテットが2のIPを指定します。



- ターゲットネットワークの指定
- 必要なターゲットネットワークを指定します。

- 認証ルールの追加
- 認証ルールを追加して、セキュリティを強化します。

- S3バケットポリシーの設定
- 以下のように、特定のVPCエンドポイントからアクセスを許可するS3バケットポリシーを設定します。
- 接続テスト
- 接続が正常に動作するか確認するため、以下のコマンドを実行してテストを行います。

一問道場
質問
ある企業が、大量のアーカイブ文書を保存し、従業員が企業のイントラネットを通じてアクセスできるようにすることを計画しています。従業員は、クライアントVPNサービスを通じてVPCに接続し、システムにアクセスします。
データは公開されるべきではありません。保存される文書は、他の物理メディアにも保管されているデータのコピーです。リクエスト数は少なく、可用性や取得速度は重要ではありません。
この要件を満たすために、最も低コストで実現できるソリューションはどれですか?
選択肢
- A
Amazon S3バケットを作成し、S3 One Zone-Infrequent Access (S3 One Zone-IA)ストレージクラスをデフォルトに設定。
S3バケットをウェブサイトホスティング用に設定し、S3インターフェースエンドポイントを作成して、バケットへのアクセスをそのエンドポイントからのみ許可する。
- B
Amazon EC2インスタンスを起動し、ウェブサーバーを実行。
Amazon Elastic File System (EFS)を接続し、EFS One Zone-Infrequent Access (EFS One Zone-IA)ストレージクラスを使用。
インスタンスのセキュリティグループを設定して、アクセスをプライベートネットワークからのみ許可する。
- C
Amazon EC2インスタンスを起動し、ウェブサーバーを実行。
Amazon Elastic Block Store (EBS)ボリュームを接続し、Cold HDD (sc1)ボリュームタイプを使用。
インスタンスのセキュリティグループを設定して、アクセスをプライベートネットワークからのみ許可する。
- D
Amazon S3バケットを作成し、S3 Glacier Deep Archiveストレージクラスをデフォルトに設定。
S3バケットをウェブサイトホスティング用に設定し、S3インターフェースエンドポイントを作成して、バケットへのアクセスをそのエンドポイントからのみ許可する。
解説
このケースでは、以下の要件があります:
- データは公開されるべきではない → アクセス制御が必要。
- 保存される文書は他の物理メディアにあるデータのコピー → 可用性や耐久性が低くても許容可能。
- リクエスト数は少なく、可用性や取得速度は重要ではない → コストを最優先。
これらの要件に基づき、最適な選択肢は以下です:
正解:D
理由:
- Amazon S3 Glacier Deep Archiveは、非常に低頻度のアクセス向けに最適化された最安価なストレージオプションです。
- データが公開されないように、S3インターフェースエンドポイントを使用し、イントラネット経由のアクセスを制御できます。
- 可用性や取得速度が重要ではないため、取得に数時間かかるGlacier Deep Archiveが適切です。
他の選択肢の考察:
- A:
- S3 One Zone-IAは低頻度アクセス向けですが、Glacier Deep Archiveほど低コストではありません。
- バケットホスティングが不要な要件である点も不適合。
- B:
- EFS One Zone-IAはコストが高く、スケールや性能が不要なこのシナリオにはオーバースペック。
- C:
- *EBS Cold HDD (sc1)**はコスト効率が良いものの、EC2を常時起動する必要があり、ストレージコスト以上に運用コストが発生します。
補足:
S3 Glacier Deep Archiveは非常に低コストですが、取得には最低12時間以上の遅延があるため、取得速度が重要な要件ではないことを再確認してから選択するのが重要です。
- 作者:みなみ
- 链接:https://www.minami.ac.cn//%E8%B3%87%E6%A0%BC%E5%8B%89%E5%BC%B7/15ad7ae8-88e2-8042-b275-f7a21d21779e
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章













